

In This Tutorial, We Are Going To Scrape Yelp Reviews Using Python. We Will Also Take A Deep Dive Into The Benefits Of Scraping Yelp, Including Lead Generation, Sentimental Analysis, Etc.
Yelp is one of the largest crowd-sourced ratings and review websites for local businesses. It is a trusted review website because of the limited amount of spam and ads. With more than 265 million public reviews on its platform, Yelp stands as a data-rich website for data miners and contributes to the credibility and authenticity of the platform.
Yelp reviews are published by everyday consumers giving a wide range of positive and negative voices and providing a comprehensive understanding of a business’s offering, tailoring to different tastes and needs.
These reviews often include images, videos, and detailed descriptions, allowing potential visitors to make informed decisions, encouraging a healthy interaction between consumers and businesses, and assisting businesses to address any concerns or problems to demonstrate their commitment to customer satisfaction.
Why Scrape Yelp?
Yelp has a mighty base of 90 million visitors per month across its website and mobile app, with users and businesses contributing to this platform day-to-day.
Gathering Yelp reviews can provide valuable insights about your competitors. By analyzing their ratings and reviews, you can know where your business stands in the market and identify the weak points hindering your business expansion.
By monitoring the negative reviews left by your customers, you can identify any issues with your business that need to be addressed promptly.
Yelp’s ultra-big size business directory can also help you generate quality leads for your business. You can also collect addresses, phone numbers, and other details by scraping Yelp.
Before we start with this blog, let me explain some requirements.
Let’s Begin scraping Yelp Reviews
Scraping Yelp Business Reviews With Node JS Is Pretty Easy. First, we will extract the overall rating and the reviews given by the customers of this restaurant.
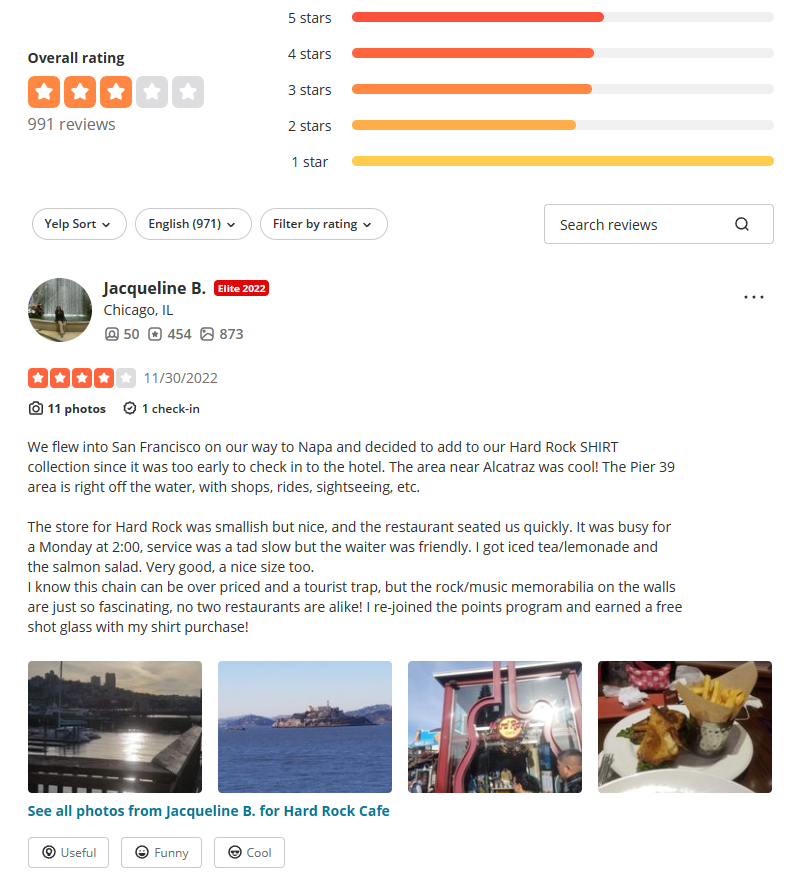
Here is a list of data that we are going to scrape in this tutorial:
- Name of the person
- Location of the person
- The review by the person
- The rating by the person
The Yelp Reviews scraping can be divided into two parts:
- Making the HTTP request on the target URL to extract the raw HTML data.
- Parsing the HTML data to extract the required information.
Set-Up
For beginners, to install Node JS on your device, you can watch these videos:
Install Libraries
To start scraping Yelp Reviews we need to install some libraries to move forward.
Or you can directly install them by running the below commands:
pip install beautifulsoup4
pip install requests
So before starting, we must ensure that we have set up our Python Project and installed both BeautifulSoup And Requests.
Process
Now, let’s start scraping Yelp Business Reviews by making a GET request on the target URL using Requests to get the raw HTML data.
import requests
from bs4 import BeautifulSoup
url = "https://www.yelp.com/biz/hard-rock-cafe-san-francisco-5"
headers={"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5042.108 Safari/537.36"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
print(response.status_code)
user_reviews = []
After importing libraries and declaring the URL and headers, we established an HTTP connection with the URL using a GET request provided by Python.
We also created a BeautifulSoup instance to navigate and extract the data from HTML.
Let us now inspect and check the HTML structure of Yelp Reviews.
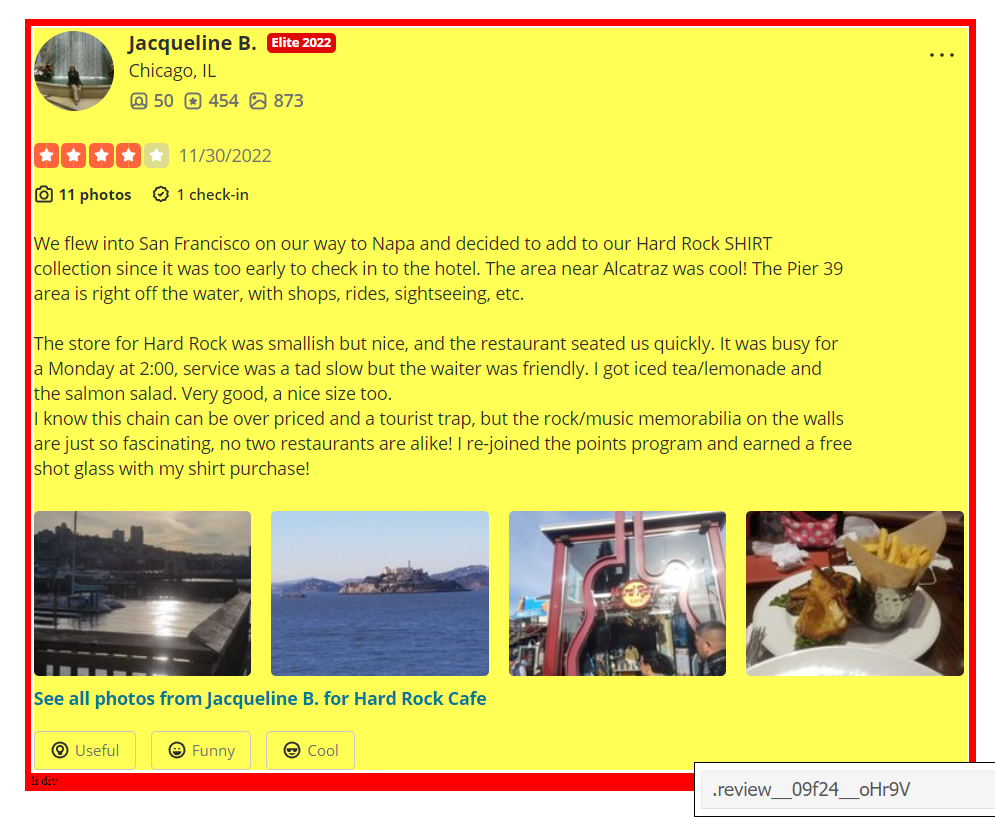
As you can see, all the reviews are contained inside a list. To extract the customer reviews, we need to run a loop at each one of them.
for review in soup.select("li.css-1q2nwpv"):
user_reviews.append({
})
Then, we need to find the tags for our respective data points. For example, the tag for the name is .css-ux5mu6 .css-19v1rkv, and the tag for the location is .css-1u1p5a2 .css-qgunke, etc. Similarly, we can find the tags for other data points.
Our parser will look like this after finding the tags for each data point.
for review in soup.select("li.css-1q2nwpv"):
user_reviews.append({
"name": review.select(".css-ux5mu6 .css-19v1rkv")[0].text,
"location": review.select(".css-1u1p5a2 .css-qgunke")[0].text,
"review": review.select(".comment__09f24__D0cxf .css-qgunke")[0].text,
"rating": review.select(".five-stars__09f24__mBKym")[0]["aria-label"],
})
Here are the results:
{
name: 'Jacqueline B.',
location: 'Chicago, IL',
review: 'We flew into San Francisco on our way to Napa and decided to add to our Hard Rock SHIRT collection since it was too early to check in to the hotel. The area near Alcatraz was cool! The Pier 39 area is right off the water, with shops, rides, sightseeing, etc. The store for Hard Rock was smallish but nice, and the restaurant seated us quickly. It was busy for a Monday at 2:00, service was a tad slow but the waiter was friendly. I got iced tea/lemonade and the salmon salad. Very good, a nice size too.I know this chain can be over priced and a tourist trap, but the rock/music memorabilia on the walls are just so fascinating, no two restaurants are alike! I re-joined the points program and earned a free shot glass with my shirt purchase!',
rating: '4 star rating',
}
Here is the complete code:
import requests
from bs4 import BeautifulSoup
url = "https://www.yelp.com/biz/hard-rock-cafe-san-francisco-5"
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5042.108 Safari/537.36"} # Add a user agent to mimic a web browser
response = requests.get(url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
user_reviews = []
for review in soup.select("li.css-1q2nwpv"):
user_reviews.append({
"name": review.select(".css-ux5mu6 .css-19v1rkv")[0].text,
"location": review.select(".css-1u1p5a2 .css-qgunke")[0].text,
"review": review.select(".comment__09f24__D0cxf .css-qgunke")[0].text,
"rating": review.select(".five-stars__09f24__mBKym")[0]["aria-label"],
})
print(user_reviews)
And that’s what a basic scraper of Yelp Reviews looks like. Similarly, this same process of scraping and selecting tags can be followed in other programming languages.
The response from the above code will be:
[
{
review: “Nice spot at Pier 39. There's rock music and videos playing!!! Wonderful!!! The food is really good! The salad was very balanced! Not watery even with noodles! The servers are attentive and friendly! Clean restrooms!”,
name: “Thanh Viet P.”,
stars: “5 star rating”,
place: “San Francisco, CA”
},
{
review: “The last time I went to a Hard Rock Cafe was years ago in Vegas, and didn't remember what it was like. After coming here, makes sense why it wasn't memorable. It's definitely a tourist spot and I was expecting a more exciting menu. Their menu is pretty limited food wise and pricey for what they serve. All they really serve is burgers and chicken sandwiches with maybe 5 other entrees to pick from. My coworker and I decided to go to Pier 39 after a work conference. We ate at the restaurant around 5:30 on a Thursday and we were seated right away. The place wasn't too busy, one large group and maybe 5 or 6 other tables were full. There was a live DJ playing. I ordered their Mac and cheese and my friend got a burger. We also got the onion ring tower and I ordered their signature hurricane with the souvenir glass for $5 more and you also get 8 oz more of the beverage. The Mac and cheese was ok, it had a strong red bell pepper flavor to it. The burger was good but the fries were bland. Our favorite item was the onion rings. They came out piping hot and crispy. The hurricane was tasty, definitely my type of tropical flavors. Overall it was alright, not a place I'd choose to go to again even if I were to bring people from out of town into the Bay. There's better options for food even for tourist spots. The restaurant was clean and service was fine.”,
name: “Elizabeth Y.”,
stars: “3 star rating”,
place: “Fremont, CA”
},
{
review: “First I have to agree with Jessica's post. If you're looking for a great meal with wonderful atmophere, Hard Rock Cafe can't be beat. Yes, it's a must visit. One reason that I chose to eat here was because I didn't want to go to the other restaurant. The other place was Bubba Gump's which was at the end of the pier. The other reason was because I am a AAA member and this was on the list. By the way, both are on the list. I ordered the Legendary Burger which when it arrived was larger than it was display on the menu. Very good and messy. It definitely came out as I ordered it. It came with French fries, but I was already too full. The service by Juliesca was excellent. Very friendly and pretty much was the only waitress around. It was not packed on an early Sunday afternoon. I would return the next time that I am back in the city.”,
name: “Samson W.”,
stars: “5 star rating”,
place: “Milpitas, CA”
},
...
]
So, this is how you can create a basic script to scrape data from Yelp.
Limitations While Scraping Yelp
Scraping data from Yelp might not be an easy task if you are considering extracting data extensively with the above-discussed method. Yelp is quite sensitive to data scraping, which can ultimately result in IP blockage.
To address this issue, you can try out a consistent solution allowing 24×7 smooth data access to Yelp. One such solution is Serpdog’s Yelp Search API.
Serpdog’s Yelp Search API offers a reliable solution to its customers to help them overcome the limitations encountered while scraping Yelp, ensuring consistent data delivery without any risk of IP blockages.
First-time users also get 1000 free credits to test out our API.
Conclusion:
In this tutorial, we learned to scrape Yelp Reviews by making a basic scraper with the help of Python. We also explored why it is essential to extract data from Yelp.
I hope you enjoyed the tutorial. Feel free to message me if I missed something. Follow me on Twitter. Thanks for reading!
Additional Resources
Want to learn more about web scraping? Not a problem! We have already prepared the list of tutorials so you can kickstart your web scraping journey.
- Web Scraping Google With Node JS – A Complete Guide
- Web Scraping Google Maps Results
- Scrape Google Shopping Results
- Scrape Google Maps Reviews
- Web Scraping Amazon