

This post will teach us to scrape Google News results with Node JS using Unirest and Cheerio.

Requirements for scraping Google News Results:
Web Parsing with CSS selectors
To search the tags from the HTML files is not only a difficult thing to do but also a time-consuming process. It is better to use the CSS Selectors Gadget for selecting the perfect tags to make your web scraping journey easier.
This gadget can help you to come up with the perfect CSS selector for your need. Here is the link to the tutorial, which will teach you to use this gadget for selecting the best CSS selectors according to your needs.
User Agents
User-Agent is used to identify the application, operating system, vendor, and version of the requesting user agent, which can save help in making a fake visit to Google by acting as a real user.
You can also rotate User Agents, read more about this in this article: How to fake and rotate User Agents using Python 3.
If you want to further safeguard your IP from being blocked by Google, you can try these 10 Tips to avoid getting Blocked while Scraping Google.
Install Libraries
To start scraping Google News Results we need to install some NPM libraries so we can move forward.
So before starting, we have to ensure that we have set up our Node JS project and installed both the packages — Unirest JS and Cheerio JS. You can install both packages from the above link.
Let’s start scraping Google News Results:
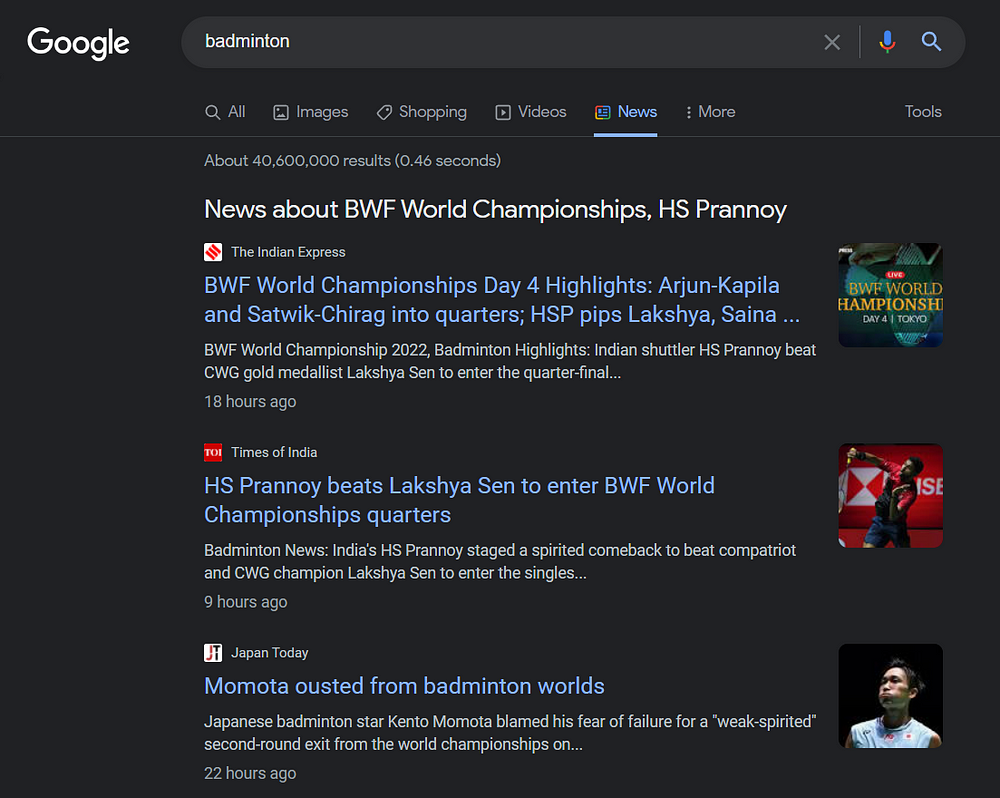
As stated above in the section Requirements, we will use Unirest JS for scraping HTML data and Cheerio JS for parsing extracted HTML data.
Here is the full code:
const unirest = require("unirest");
const cheerio = require("cheerio");
const getNewsData = () => {
return unirest
.get("https://www.google.com/search?q=football&gl=us&tbm=nws")
.headers({
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
})
.then((response) => {
let $ = cheerio.load(response.body);
let news_results = [];
$(".BGxR7d").each((i,el) => {
news_results.push({
link: $(el).find("a").attr('href'),
title: $(el).find("div.mCBkyc").text(),
snippet: $(el).find(".GI74Re").text(),
date: $(el).find(".ZE0LJd span").text(),
thumbnail: $(el).find(".NUnG9d img").attr("src")
})
})
console.log(news_results)
});
};
getNewsData(); Or you can copy this code from the following link for better understanding: GoogleNewsScraper.
Code Explanation:
First, we declare constants from libraries:
const unirest = require("unirest");
const cheerio = require("cheerio"); Next, we used Unirest JS for making a get request to our target URL which in this case is:
https://www.google.com/search?q=Badminton&gl=us&tbm=nws
We will make this request by passing the headers to the URL, which in this case is User-Agent.
User-Agent is used to identify the application, operating system, vendor, and version of the requesting user agent, which can save help in making a fake visit to Google by acting as a real user.
.headers({
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
}) You can also pass the proxy URL while requesting this:
.get("https://www.google.com/search?q=Badminton&gl=us&tbm=nws")
.headers({
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
})
.proxy("PROXY URL") Here “PROXY URL” refers to the proxy server URL you will use for making the requests. It can help you in hiding your real IP address which means the website you are scraping will not be able to identify your real IP address, thus saving you from being blocked. Then we load our response in the Cheerio variable and initialize an empty array “news_results” to store our data.
Then we load our response in the Cheerio variable and initialize an empty array news_results to store our data.
.then((response) => {
console.log(response.body)
let $ = cheerio.load(response.body);
let news_results = []; 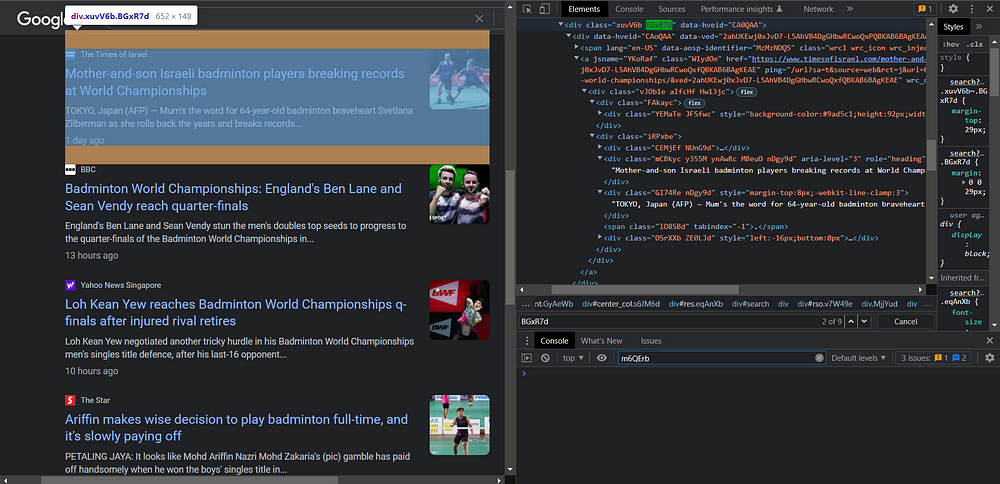
You can see that every news article is contained this BGxR7d tag. By searching in this container, you will get the tag for the title as mCBkyc, description as GI74Re, date as ZE0LJd span , and for the image as NUnG9d img.
And then a parser to get the required information:
$(".BGxR7d").each((i,el) => {
news_results.push({
link: $(el).find("a").attr('href'),
title: $(el).find("div.mCBkyc").text().replace("\n",""),
snippet: $(el).find(".GI74Re").text().replace("\n",""),
date: $(el).find(".ZE0LJd span").text(),
thumbnail: $(el).find(".NUnG9d img").attr("src")
})
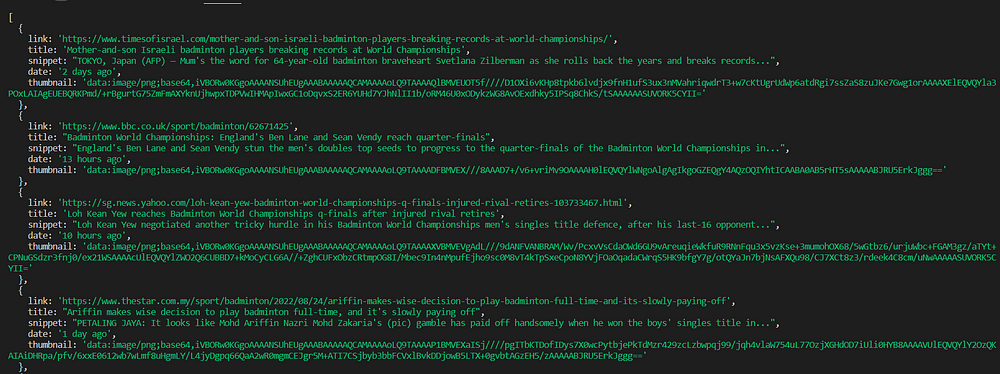
}) Run this code in your terminal and you will get the results like this:
With Google News API
If you don’t want to code and maintain the scraper in the long run then you can try our Google News API to scrape News Results.
We also offer 100 free requests on the first sign-up.
After getting registered on our website, you will get an API Key. Embed this API Key in the below code, you will be able to scrape Google News Results at a much faster speed.
const axios = require('axios');
axios.get('https://api.serpdog.io/news?api_key=APIKEY&q=football&gl=us')
.then(response => {
console.log(response.data);
})
.catch(error => {
console.log(error);
}); Conclusion:
In this tutorial, we learned to scrape Google News Results using Node JS. Feel free to message me anything you need clarification on. Follow me on Twitter. Thanks for reading!
Additional Resources
- How to scrape Google Organic Search Results using Node JS?
- Scrape Google Images Results
- Scrape Google Shopping Results
- Scrape Google Maps Reviews
Frequently Asked Questions
Q. Can you scrape Google News Results?
Yes, Serpdog API can scrape Google News Results and can withstand millions of API calls per second without any problem of blockage and CAPTCHAs.
Q. How do I scrape Google News Results for free?
- Login to Serpdog | Google Search API.
- Insert the query you want to scrape from Google.
- Click the Send button to send the request to the API server and collect your response from the dashboard.