

Yelp is one of the largest crowd-sourced ratings and review websites for local businesses. It is a trusted review website because of the limited amount of spam and ads. With more than 265 million public reviews on its platform, Yelp stands as a data-rich website for data miners and contributes to the credibility and authenticity of the platform.
Yelp’s ultra-big size business directory can also help you generate quality leads for your business. You can collect addresses, phone numbers, and other details from this business directory.
Additionally, gathering Yelp reviews can provide valuable insights about your competitors. By analyzing their ratings and reviews, you can know where your business stands in the market and identify the weak points hindering your business expansion.
In This Tutorial, We Are Going To Scrape Yelp Using Python. We Will Also Take A to explore its benefits in Generating leads and Sentimental Analysis, Etc.
Let’s Begin scraping
Scraping Yelp Restaurant Data with Python Is pretty easy. We are going to target this restaurant page for this tutorial.

Here is a list of data that we are going to scrape in this tutorial:
- Name of the Restaurant
- Address of the Restaurant
- Specialty
- Rating and Reviews
The Yelp Reviews scraping can be divided into two parts:
- Making the HTTP request on the target URL to extract the raw HTML data.
- Parsing the HTML data to extract the required information.
Set-Up
For beginners, to install Python on your device, you can watch these videos:
Install Libraries
To start the tutorial, we will install some libraries to move forward.
Or you can directly install them by running the below commands:
pip install beautifulsoup4
pip install requests
So before starting, we must ensure that we have set up our Python Project and installed both BeautifulSoup And Requests.
Process
Since we have already decided on the data points we are going to target and have also installed the required libraries, let us now proceed to prepare our scraper.
import requests
from bs4 import BeautifulSoup
url = "https://www.yelp.com/biz/hard-rock-cafe-san-francisco-5"
headers={"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5042.108 Safari/537.36"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
print(response.status_code)
l=list()
obj={}
After importing libraries and declaring the URL and headers, we established an HTTP connection with the URL using a GET request provided by Python.
We also created a BeautifulSoup instance to navigate and extract the data from HTML.
Let us inspect and check the HTML structure to get the desired data.
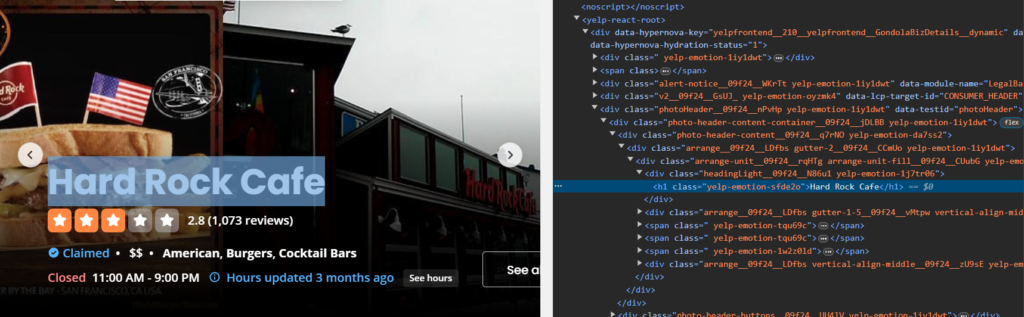
As you can see, the restaurant name is inside the h1 tag
try:
obj["name"]=soup.select_one("h1").text
except:
obj["name"]=None
Similarly, we can find the tag for the address.

So, the address can be found under the tag p with the class yelp-emotion-y7d6x3.
try:
obj["address"]=soup.select_one(".yelp-emotion-y7d6x3").text
except:
obj["address"]=None
Then, we will find the tag for the restaurant’s specialty.
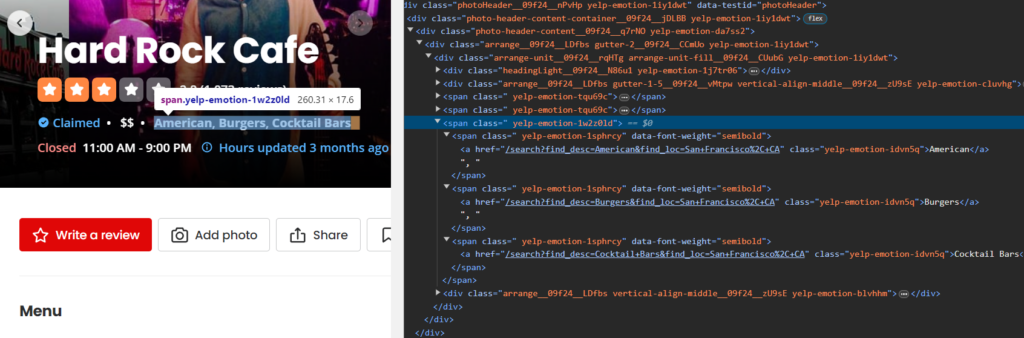
The specialty is contained inside the span tag with the class yelp-emotion-1w2z0ld.
try:
obj["specialty"]=soup.select_one(".yelp-emotion-1w2z0ld").text
except:
obj["specialty"]=None
Finally, we will extract the rating and reviews of the restaurant.
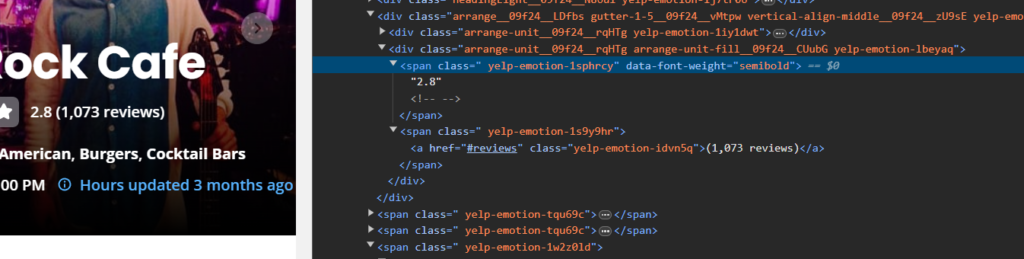
So, the rating is under the tag span with the class yelp-emotion-1sphrcy and the number of reviews is also located inside the span tag with the class yelp-emotion-idvn5q.
try:
obj["rating"]=soup.select_one(".yelp-emotion-1sphrcy").text
except:
obj["rating"]=None
try:
obj["reviews"]=soup.select_one(".yelp-emotion-idvn5q").text
except:
obj["reviews"]=None
Here is the complete code:
import requests
from bs4 import BeautifulSoup
url = "https://www.yelp.com/biz/hard-rock-cafe-san-francisco-5"
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5042.108 Safari/537.36"} # Add a user agent to mimic a web browser
response = requests.get(url, headers=headers)
print(response.status_code)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
l=list()
obj={}
try:
obj["name"]=soup.select_one("h1").text
except:
obj["name"]=None
try:
obj["address"]=soup.select_one(".yelp-emotion-y7d6x3").text
except:
obj["address"]=None
try:
obj["specialty"]=soup.select_one(".yelp-emotion-1w2z0ld").text
except:
obj["specialty"]=None
try:
obj["rating"]=soup.select_one(".yelp-emotion-1sphrcy").text
except:
obj["rating"]=None
try:
obj["reviews"]=soup.select_one(".yelp-emotion-idvn5q").text
except:
obj["reviews"]=None
l.append(obj)
obj={}
print(l)
And that’s what a basic scraper of Yelp looks like. Similarly, other programming languages can follow this same process of scraping and selecting tags.
The response from the above code will be:
[{
'name': 'Hard Rock Cafe',
'address': 'Pier 39 Space 256 Bldg Q, Level 1 San Francisco, CA 94133',
'specialty': 'American, Burgers, Cocktail Bars',
'rating': '2.8 ',
'reviews': '(1,073 reviews)'
}]
So, this is how you can create a basic script to scrape data from Yelp.
Limitations While Scraping Yelp
Scraping data from Yelp might not be easy if you consider extracting data extensively with the above-discussed method. Yelp is quite sensitive to data scraping, which can ultimately result in IP blockage.
To address this issue, you can try a consistent solution allowing 24×7 smooth data access to Yelp. One such solution is Serpdog’s Yelp Scraper API.
Serpdog’s Yelp Scraper API offers a reliable solution to its customers to help them overcome the limitations encountered while scraping Yelp, ensuring consistent data delivery without any risk of IP blockages.
First-time users also get 1000 free credits to test out our API.
Conclusion:
In this tutorial, we learned to scrape Yelp by making a basic scraper with the help of Python. We also explored why it is essential to extract data from Yelp.
I hope you enjoyed the tutorial. Feel free to message me if I missed something. Follow me on Twitter. Thanks for reading!
Additional Resources
Want to learn more about web scraping? Not a problem! We have already prepared the list of tutorials so you can kickstart your web scraping journey.
- Web Scraping Google With Node JS – A Complete Guide
- Web Scraping Google Maps Results
- Scrape Google Shopping Results
- Scrape Google Maps Reviews
- Web Scraping Amazon
