

JavaScript has the potential to become the most popular library for web scraping. The rise of its popularity is because it provides a great environment for web scraping and also offers a couple of powerful libraries like Axios, Puppeteer, Playwright, etc.
Developers are performing various tasks nowadays using JavaScript, such as making web applications, games, mobile apps, etc. And one such beautiful task it can do is scraping Google Search Results.
In This Tutorial, We Will Be Scraping Google Search Results With Node JS Using Unirest And Cheerio As Web Scraping Libraries.
Why Scrape Google Search Results?
Scraping Google Search Results can provide you with various benefits:
Rank Tracking – It will help you to get data about your website’s position on the search engine, optimize your website for particular keywords, etc.
Lead Generation – Scraping Google can provide you with every piece of information available about a person who can be your potential customer.
Price Tracking – It also helps to track the pricing of particular products from various sources which is a great thing for saving both time and resources.
Let’s start Scraping Google Search Results:
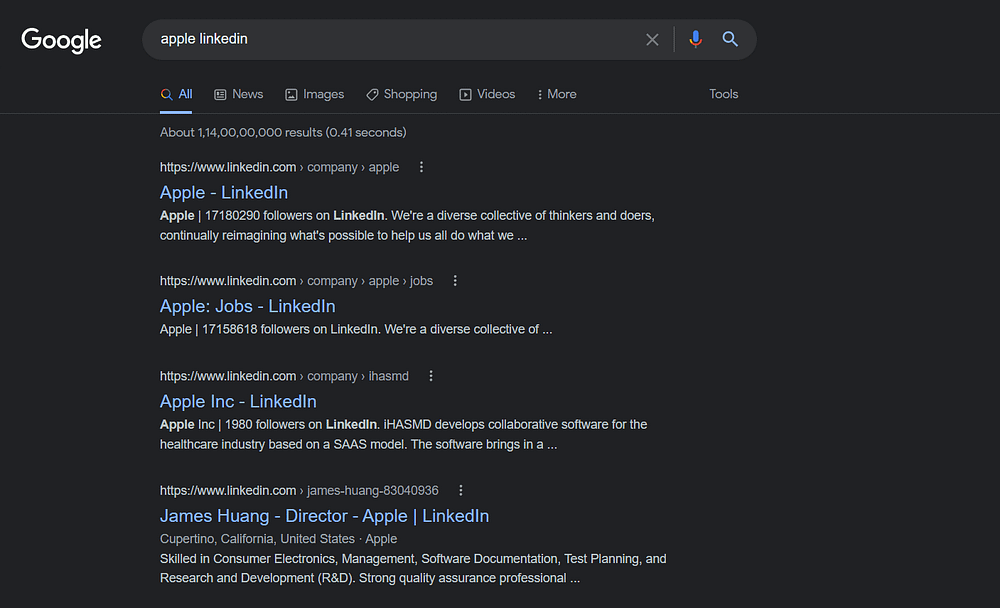
Requirements
To start scraping Google Search Results, we need to install some npm libraries to move forward and prepare our scraper.
To extract our HTML data we will use Unirest JS. And for parsing the HTML data, we will use Cheerio JS.
Process
The Google Search Results scraping is divided into two parts:
- Making HTTP requests on the target URL to extract the raw HTML data.
- Parsing the HTML data to extract the required data.
We will first target this URL:
https://www.google.com/search?q=apple+linkedin&gl=us&hl=en
We will make this request by passing the headers to the URL, which in this case is User-Agent.
User-Agent is used to identify the application, operating system, vendor, and version of the requesting user agent, which can help in making a fake visit to Google by acting as a real user.
You can also rotate User Agents, read more about this in this article: How to fake and rotate User Agents using Python 3
If you want to further safeguard your IP from being blocked by Google, you can use Serpdog’s Google Search API which solves all the problems of proxies and CAPTCHAs for a smooth scraping journey.
unirest
.get("https://www.google.com/search?q=apple+linkedin&gl=us&hl=en")
.headers({
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
})
.proxy("PROXY SERVER URL")
Now, we will search for the required tags from HTML for our title, description, link, and displayed link.
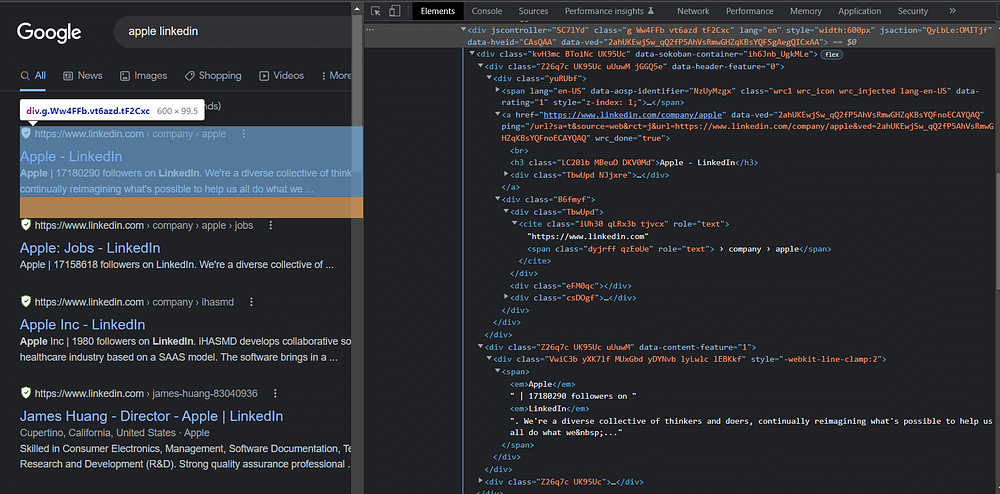
So, according to this image, the tag for the title is .yuRUbf > a > h3 , for the link is .yuRUbf > a , for the snippet is .g .VwiC3b and for the displayed link is .g .yuRUbf .NJjxre .tjvczx.
Here is our code:
const unirest = require("unirest");
const cheerio = require("cheerio");
const getOrganicData = () => {
return unirest
.get("https://www.google.com/search?q=apple+linkedin&gl=us&hl=en")
.headers({
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
})
.then((response) => {
let $ = cheerio.load(response.body);
let titles = [];
let links = [];
let snippets = [];
let displayedLinks = [];
$(".yuRUbf > a > h3").each((i, el) => {
titles[i] = $(el).text();
});
$(".yuRUbf > a").each((i, el) => {
links[i] = $(el).attr("href");
});
$(".g .VwiC3b ").each((i, el) => {
snippets[i] = $(el).text();
});
$(".g .yuRUbf .NJjxre .tjvcx").each((i, el) => {
displayedLinks[i] = $(el).text();
});
const organicResults = [];
for (let i = 0; i < titles.length; i++) {
organicResults[i] = {
title: titles[i],
links: links[i],
snippet: snippets[i],
displayedLink: displayedLinks[i],
};
}
console.log(organicResults)
});
};
getOrganicData();
Or you can copy this code from the following link for better understanding: Google Organic Search Results Scraper
Results:
Our result should look like this 👇🏻.
[
{
title: 'Apple - LinkedIn',
links: 'https://www.linkedin.com/company/apple',
snippet: "Apple | 17180290 followers on LinkedIn. We're a diverse collective of thinkers and doers, continually reimagining what's possible to help us all do what we ...",
displayedLink: 'https://www.linkedin.com › company › apple'
},
{
title: 'Apple: Jobs - LinkedIn',
links: 'https://www.linkedin.com/company/apple/jobs',
snippet: "Apple | 17158618 followers on LinkedIn. We're a diverse collective of ...",
displayedLink: 'https://www.linkedin.com › company › apple › jobs'
},
{
title: 'Apple Inc - LinkedIn',
links: 'https://www.linkedin.com/company/ihasmd',
snippet: 'Apple Inc | 1980 followers on LinkedIn. iHASMD develops collaborative software for the healthcare industry based on a SAAS model. The software brings in a ...',
displayedLink: 'https://www.linkedin.com › company › ihasmd'
},
{
title: 'James Huang - Director - Apple | LinkedIn',
links: 'https://www.linkedin.com/in/james-huang-83040936',
snippet: 'Skilled in Consumer Electronics, Management, Software Documentation, Test Planning, and Research and Development (R&D). Strong quality assurance professional ...',
displayedLink: 'https://www.linkedin.com › james-huang-83040936'
},
....
Using Google Search API to scrape Google
If you don’t want to code and maintain the scraper in the long run then you can try this Google Search API to scrape Google Search Results. Serpdog APIs also support all advanced featured snippets like knowledge graphs, answer box results, etc.
We also offer 100 free requests on the first sign-up.
After registering on our website, you will get an API Key which you can embed in the below code to scrape the Google Search Results Using Node JS.
const axios = require('axios');
axios.get('https://api.serpdog.io/search?api_key=APIKEY&q=coffee&gl=us')
.then(response => {
console.log(response.data);
})
.catch(error => {
console.log(error);
});
Result:
"organic_results": [
{
"title": "9 Health Benefits of Coffee, Based on Science - Healthline",
"link": "https://www.healthline.com/nutrition/top-evidence-based-health-benefits-of-coffee",
"displayed_link": "https://www.healthline.com › Wellness Topics › Nutrition",
"snippet": "Coffee is a popular beverage that researchers have studied extensively for its many health benefits, including its ability to increase energy levels, promote ...",
"rank": 1
},
{
"title": "The Coffee Bean & Tea Leaf | CBTL",
"link": "https://www.coffeebean.com/",
"displayed_link": "https://www.coffeebean.com",
"snippet": "Born and brewed in Southern California since 1963, The Coffee Bean & Tea Leaf® is passionate about connecting loyal customers with carefully handcrafted ...",
"rank": 2
},
{
"title": "Peet's Coffee: The Original Craft Coffee",
"link": "https://www.peets.com/",
"displayed_link": "https://www.peets.com",
"snippet": "Since 1966, Peet's Coffee has offered superior coffees and teas by sourcing the best quality coffee beans and tea leaves in the world and adhering to strict ...",
"rank": 3
},
....
],
Conclusion:
In this tutorial, we learned to scrape Google Search Results using Node JS. Feel free to message me anything you need clarification on. Follow me on Twitter Thanks for reading!
Additional Resources
- Scrape Google Shopping Results
- Scrape Google Images Results
- Scrape Google News Results
- Scrape Google Maps Reviews
Frequently Asked Questions
Can you scrape Google Search results?
If you don’t want to code and maintain the scraper in the long run, you can try Serpdog Google Search API to scrape Google search results. This API also supports all advanced featured snippets like Knowledge Graphs, Answer Box results, etc.
How do I scrape Google Search results for free?
1. Log in to the Serpdog Google Search API.
2. Enter the query you want to scrape from Google.
3. Click the send button to submit the request to the API server and collect your response from the dashboard.
