
Many businesses depend on web scraping for informed data-driven decisions as they know a strong foothold in the market demands access to competitor’s data. However, it is also essential to use efficient software and applications for web scraping tasks to ensure consistent data collection.
This is why only selected languages stand out in the list and are preferred as reliable web scraping languages. Python is the most preferred language for web scraping, which is highly scalable and easy to learn with clear syntax. Node JS is another popular language for web scraping backed by libraries like Axios and Puppeteer.
There may be other options available depending on the criteria, but these are the most preferred choices. Let us now discuss the most popular languages for web scraping in 2023.
Python
Python is regarded as the most popular language for web scraping because of its versatility, scalability, and ease of use. It can not only complete data extraction-related tasks but can also be utilized for comprehensive data analysis by using its powerful machine learning modules.
Moreover, Python has a massive ecosystem of libraries constantly updated by its large community, simplifying the process of scraping and parsing the content. There are various communities and forums related to Python on Reddit and Discord where programmers can easily find solutions to any problem regarding their web scraping programs.
Python provides various libraries specifically designed for performing web scraping tasks. BeautifulSoup is a highly efficient and simple-to-use Python library that can collect data from poorly written HTML and XML pages at a rapid pace, which is a much-needed feature when you are dealing with huge chunks of data.
Scrapy is an open-source Python framework that offers impressive features like multithreading, crawling, and tools for debugging. It can be highly useful and efficient when used for large scraping projects.
Overall, if you are considering Python for your next web scraping project, then I believe you are among the right group of people. With all the features offered by Python, it is even easy to deal with complex web scraping projects.
JavaScript
JavaScript used to be a front-end language until NodeJS came and pushed its abilities to the server. This excellent decision established a new contender for top web scraping languages.
With the help of the NodeJS environment, not only static websites but also dynamic websites like Yelp and Instagram are easily scraped using libraries like Puppeteer and Playwright JS.
Node JS environment can be used to create a robust and efficient scraping infrastructure using libraries like Express JS, Axios, and Cheerio. Axios is the most popular HTTP request library that provides a consistent and easy-to-use interface to scrape data from APIs and other web sources. Cheerio JS is a lightweight HTML parsing library in JavaScript based on JQuery that can easily extract any piece of content from the HTML and XML document at a rapid pace.
Advantages of using Node JS:
- It supports simple syntax, allowing beginners to learn the basics of the language quickly.
- It can handle a high number of concurrent requests simultaneously, which is a crucial feature for large-scale web scraping projects.
- It has vast community support and maintained an 11-year streak as the most commonly used language in the StackOverflow survey of 2023.
As web scraping will continue to be a vital technique in acquiring data from web sources, Node JS, with the backing of its strong developer community, will continue its dominance in extracting and analyzing data from the web.
Go
Go is another powerful language, alongside Python and JavaScript, that can be used for web scraping. It offers excellent support for concurrency, allowing multiple threads to run in parallel, thereby increasing the efficiency and speed of the scraping process.
Go’s built-in libraries already provide support for creating HTTP connections and parsing HTML, making it relatively straightforward to develop web scrapers that don’t require additional resources for their execution.
Moreover, Go is also known for its extreme performance, which can optimize the web scraping process involving large volumes of data handling. It can decrease the execution time and improve latency with the help of an excellent garbage collection mechanism.
However, Go is still a growing language in the programming community, but it has built a quality infrastructure making it an alternative to even the old powerful languages.
Ruby
Ruby’s ease of use and simplicity just cannot be ignored. This open-source language is easy to learn for any beginner without any hassle. It is not very popular in web scraping but offers specific features for smooth data extraction.
The Nokogiri library in Ruby, a powerful and popular ruby gem, provides a straightforward API to deal with broken HTML and XML documents. It supports the CSS and XPath selectors and is built with quality infrastructure, making it faster than many pure Ruby libraries.
Although Ruby is not a popular language for web scraping, it provides us with a variety of advantages:
- A combination of HTTParty and Nokogiri can set up a web scraper without any trouble.
- HTTParty can be utilized to send all types of HTTP requests to the target website and can also automatically parse the JSON and XML responses.
- Less amounts of code are needed for small scraping tasks.
Ruby provides an excellent testing environment and other advanced features. However, small community support, non-detailed documentation of the libraries, and poor multithreading explain why Ruby is still not an ideal web scraping language like Node JS and Python for large projects.
Java
One should not be surprised when presented with the fact that Java is still the 3rd most popular programming language in the world after JavaScript and Python. It has strong community support and provides quality in-built libraries and frameworks designed to simplify tasks for developers.
The JSoup library in Java provides a complete package. It can establish HTTP connections with target websites and parse the extracted HTML content to get the required information from the HTML tree.
HTMLUnit is another excellent work by the Java developer community. It can be used to scrape dynamic web pages and perform various functions, such as submitting forms and clicking links to interact with web pages.
Additionally, Java is a multithreading language that allows developers to perform multiple scraping tasks simultaneously. This feature saves a significant amount of time and resources for developers and improves their productivity.
To put it simply, Java offers various leverages like robust performance, regular maintenance, and platform independence. However, it still has a limited ecosystem for web scraping and requires more lines to achieve the functionality compared to Python and Node JS, making it a subpar choice from the top two.
C++
C++ is an object-oriented programming language characterized by features such as inheritance, polymorphism, and operator overloading, among others. It offers a fast and high-performance solution for web scraping, but it is relatively expensive to implement. Additionally, the C++ community is still larger than most popular languages and has developed quality libraries, enhancing its usability and versatility.
As we know, C++ is an old-school language, but it also provides libraries designed to keep web scraping in mind. The libcurl library, which is a popular open-source library, provides an easy-to-use API for performing HTTP requests. Another open-source library Gumbo, can be used to parse and extract information from the HTML tree.
However, keeping the performance aside, it has some disadvantages:
- Hard to learn — C++ offers a steeper learning path for beginners. Its syntax is not clear and is difficult to understand.
- Parsing HTML — Parsing complex HTML documents can be time-consuming and resource-demanding in C++.
- Complexity — Code is not easy to maintain in the long term, and there might be a possibility you might not get a specific functionality from the library, leaving you with only one choice to implement the functionality yourself from scratch.
While C++ still largely remains a popular language, implementing web scraping tasks can be time-consuming and will require a team of experts, making it an unaffordable language for an already tight web scraping market.
PHP
PHP is a server-side scripting language primarily designed for web development and for creating dynamic web pages. However, it may not be an ideal choice for web scraping, but libraries like cURL can scrape HTML content from web pages, including images, videos, text, etc.
PHP also supports well-known libraries like Goutte, which allows efficient web scraping among other libraries like HTML Dom Parser, Guzzle, etc. Goutte is particularly useful for websites that do not require JS rendering and provides a straightforward method to crawl websites and extract data using CSS selectors.
Moreover, Guzzle offers more features like handling authentication and managing request and response bodies. Another library based on Goutte, known as Symfony Panther, supports the headless browser functionality. It extends the features of Goutte by providing a sophisticated functionality similar to Puppeteer in JS such as filling out forms, mouse-clicking, and other tasks required for modern web applications.
In a nutshell, PHP is well-suited for simple web scraping projects. The poor concurrency model, lack of a rich ecosystem, and fading community support justify why PHP is not a preferred choice for web scraping.
Conclusion
So, these were the top 6 programming languages preferred for most of the scraping projects. It is not a compulsion to choose only Python, referred to as the best by web scraping gurus. Conducting thorough research will give you the most suitable language based on the project parameters, allowing you to choose the best language accordingly.
I have also prepared a comparison chart based on certain parameters that you can consider before deciding on any language for web scraping.
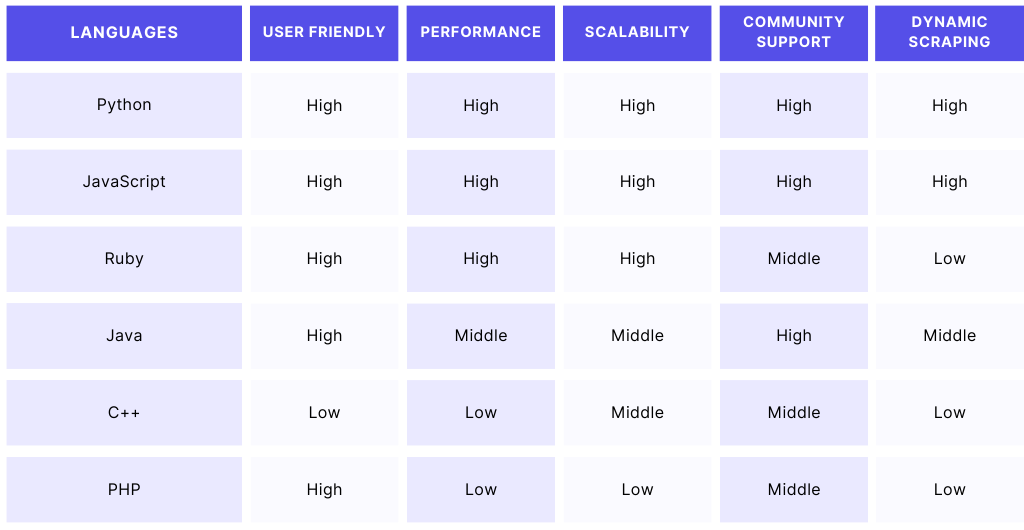
I hope this tutorial gave you a complete overview of selecting the best programming language for your project requirements. Please do not hesitate to message me if I missed something.
If you think we can complete your custom scraping projects, feel free to contact us. Follow me on Twitter. Thanks for reading!
Additional Resources
I have prepared a complete list of blogs to learn web scraping that can give you an idea and help you in your web scraping journey.