
Google Maps should not be viewed solely as a navigation platform but rather as a vast repository of businesses spanning from low-tier to upper-tier, containing extensive amounts of valuable data, including contact numbers, emails, and customer reviews.
Customer Reviews are one of the most important entities for judging the reputation of any business. It provides valuable insights into the services the company offers and its customers’ overall sentiment. This article will scrape Google Maps Reviews using Python and its libraries - Beautiful Soup and Requests.
You can also check out our article on scraping Google Maps before proceeding with this one.
The benefits of Scraping Google Maps Reviews for businesses
Google Maps Reviews are an invaluable asset for businesses. It allows them to build a sense of trust among their customers and helps them identify any concerns in their services that need to be addressed immediately. Here are some of the advantages businesses can avail by scraping Google Maps Reviews:
Valuable Insights – Scraping Google Reviews can provide valuable insights from your customers, their opinions, and feedback, which can help you to improve your product and revenue growth.
Competitive Intelligence – Reviews from Google Maps can help you identify your competitors’ strengths and weaknesses, and you can leverage this data to stay ahead of your competitors.
Data Analysis – The review data can be used for various research purposes such as sentimental analysis, consumer behavior, etc.
Reputation Management – Monitoring or analyzing the negative reviews left by your customers helps you identify the weaknesses in your product and allows you to solve problems your customers face.
Let’s Start Scraping
In this blog, we will design a Python script to scrape the top 10 Google Reviews, including location information, user details, and much more. Additionally, we will look for a method to extract reviews beyond the top 10 results.
The Google Maps Reviews scraping is divided into two parts:
- Getting the raw HTML from the target URL.
- Extracting the required review information from the HTML.
Set-Up:
Those who have not installed Python on their device can watch these videos:
If you don’t want to watch these videos, you can directly download Python from their official website.
Requirements:
To scrape Google Maps Reviews, we will be using these two Python libraries:
- Beautiful Soup – Used for parsing the raw HTML data.
- Requests – Used for making HTTP requests.
To install these libraries, you can run the below commands in your terminal:
pip install requests
pip install beautifulsoup4
Process:
After completing the setup, open the project file in your respective code editor and import the libraries we have installed above.
import requests
from bs4 import BeautifulSoup
Then, we will create our function to scrape the reviews from Google Maps Of Burj Khalifa.
def get_reviews_data():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
response = requests.get("https://www.google.com/async/reviewDialog?hl=en_us&async=feature_id:0x3e5f43348a67e24b:0xff45e502e1ceb7e2,next_page_token:,sort_by:qualityScore,start_index:,associated_topic:,_fmt:pc", headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
location_info = {}
data_id = ''
token = ''
In the above code, first, we set headers to the user agent so that our bot can mimic an organic user. Then, we made an HTTP request on our target URL.
Let us decode this URL first:
https://www.google.com/async/reviewDialog?hl=en_us&async=feature_id:0x3e5f43348a67e24b:0xff45e502e1ceb7e2,next_page_token:,sort_by:qualityScore,start_index:,associated_topic:,_fmt:pc
feature_id – It is also known as a data ID. It is a unique ID for a particular location on Google Maps.next_page_token – It is used to get the following page results.sort_by – It is used for filtering the results.
You can get the data ID of any place by searching it on Google Maps.
Let us search for Burj Khalifa on Google Maps.
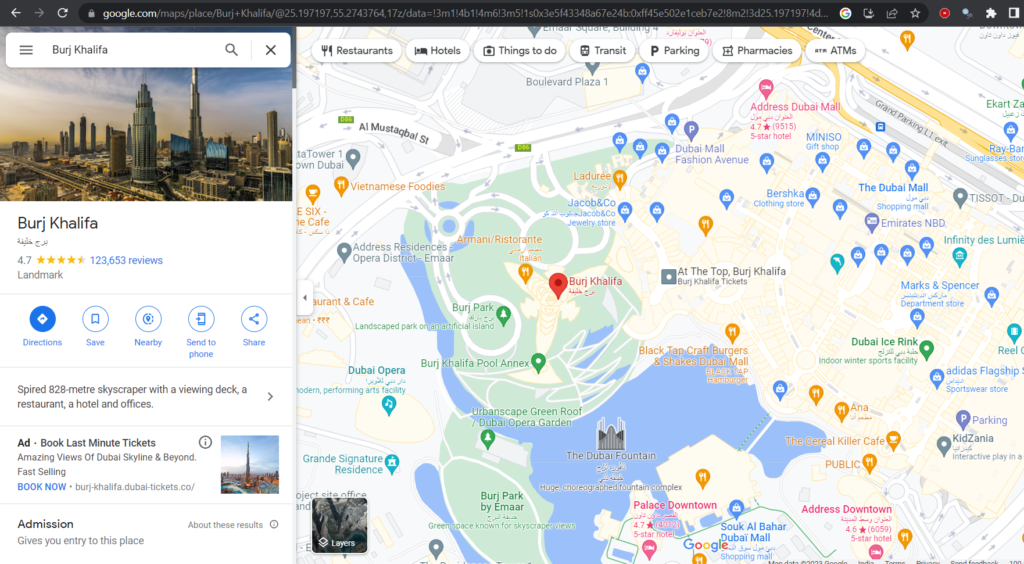
If you take a look at the URL, you will get to know the data ID is between !4m7!3m6!1s and !8m2!, which in this case is 0x3e5f43348a67e24b:0xff45e502e1ceb7e2.
Now, open the below URL in your browser.
https://www.google.com/async/reviewDialog?hl=en_us&async=feature_id:0x3e5f43348a67e24b:0xff45e502e1ceb7e2,next_page_token:,sort_by:qualityScore,start_index:,associated_topic:,_fmt:pc
A text will be downloaded to your computer. Open this text file in your code editor, and convert it into an HTML file.
We will now search for the tags of the elements we want in our response.
Let us extract the information about the location from the HTML.
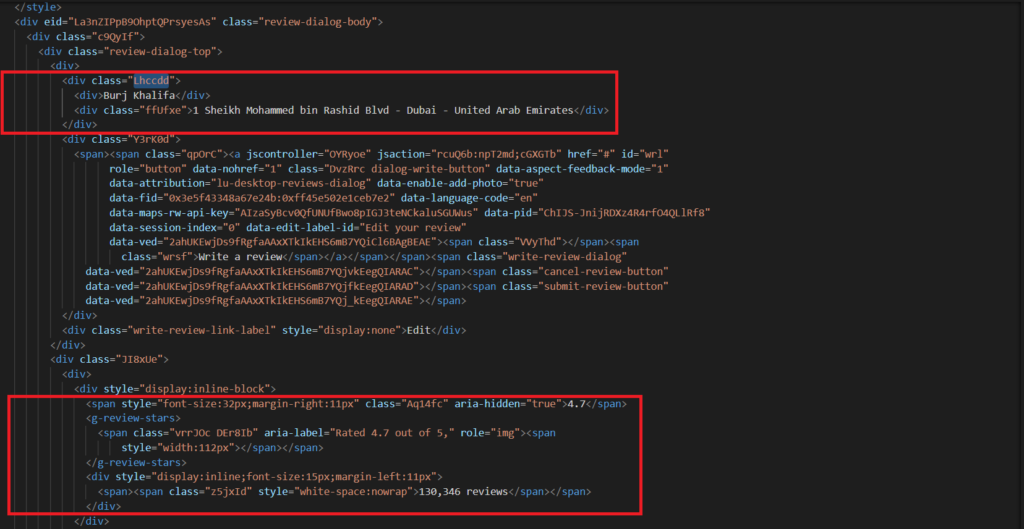
Look at the above image, you will find the tag for the title as Lhccdd, for the address as ffUfxe, for the average rating, is span.Aq14fc, and then for the total reviews is span.z5jxId.
location_info = {
'title': soup.select_one('.Lhccdd div:nth-child(1)').text.strip(),
'address': soup.select_one('.ffUfxe').text.strip(),
'avgRating': soup.select_one('span.Aq14fc').text.strip(),
'totalReviews': soup.select_one('span.z5jxId').text.strip()
}
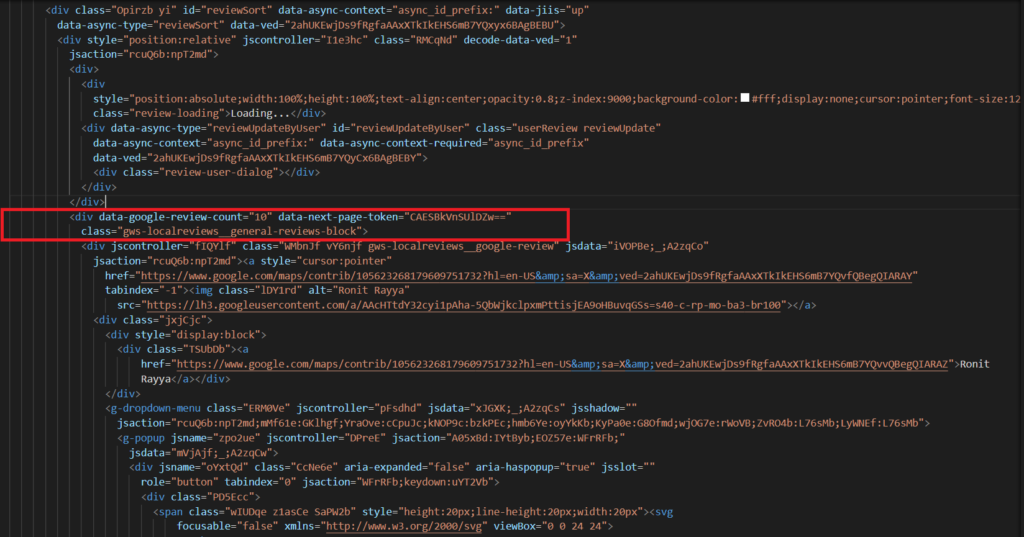
Now, we will extract the data ID and the next page token.
Search for the tag loris in the HTML. You will find the data ID in the attribute data-fid. Then search for the tag gws-localreviews__general-reviews-block, and you will find the next page token in its attribute data-next-page-token.
data_id = soup.select_one('.loris')['data-fid']
token = soup.select_one('.gws-localreviews__general-reviews-block')['data-next-page-token']
location_info = {
'title': soup.select_one('.Lhccdd div:nth-child(1)').text.strip(),
'address': soup.select_one('.ffUfxe').text.strip(),
'avgRating': soup.select_one('span.Aq14fc').text.strip(),
'totalReviews': soup.select_one('span.z5jxId').text.strip()
}
Similarly, we can extract the user’s details and other information like images posted by the user, his rating, the number of reviews, and the feedback about the location written by the user.
This makes our code look like this:
import requests
from bs4 import BeautifulSoup
def get_reviews_data():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
response = requests.get("https://www.google.com/async/reviewDialog?hl=en_us&async=feature_id:0x3e5f43348a67e24b:0xff45e502e1ceb7e2,next_page_token:,sort_by:qualityScore,start_index:,associated_topic:,_fmt:pc", headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
location_info = {}
data_id = ''
token = ''
data_id = soup.select_one('.loris')['data-fid']
token = soup.select_one('.gws-localreviews__general-reviews-block')['data-next-page-token']
location_info = {
'title': soup.select_one('.Lhccdd div:nth-child(1)').text.strip(),
'address': soup.select_one('.ffUfxe').text.strip(),
'avgRating': soup.select_one('span.Aq14fc').text.strip(),
'totalReviews': soup.select_one('span.z5jxId').text.strip()
}
reviews_results = []
for el in soup.select('.gws-localreviews__google-review'):
name = el.select_one('.TSUbDb').get_text()
link = el.select_one('.TSUbDb a')['href']
thumbnail = el.select_one('.lDY1rd')['src']
reviews_text = el.select_one('.Msppse').get_text()
if "Local" in reviews_text:
reviews = reviews_text.split("·")[1].replace(" reviews", "")
else:
reviews = reviews_text.split("·")[0].replace(" review", "").replace("s", "")
rating = el.select_one('.BgXiYe .lTi8oc')['aria-label'].split("of ")[1]
duration = el.select_one('.BgXiYe .dehysf').get_text()
snippet = el.select_one('.Jtu6Td span[jscontroller="MZnM8e"]').get_text().replace("\n", "")
if el.select_one('.Jtu6Td span[jscontroller="MZnM8e"] div.JRGY0'):
snippet = snippet.replace(el.select_one(".Jtu6Td span[jscontroller='MZnM8e'] div.JRGY0").get_text(), "")
reviews_results.append({
'name': name,
'link': link,
'thumbnail': thumbnail,
'reviews': reviews,
'rating': rating,
'duration': duration,
'snippet': snippet,
})
print("LOCATION INFO:")
print(location_info)
print("DATA ID:")
print(data_id)
print("TOKEN:")
print(token)
print("USER:")
for result in reviews_results:
print(result)
print("--------------")
get_reviews_data()
Run this code in your terminal, and your results should look like this:
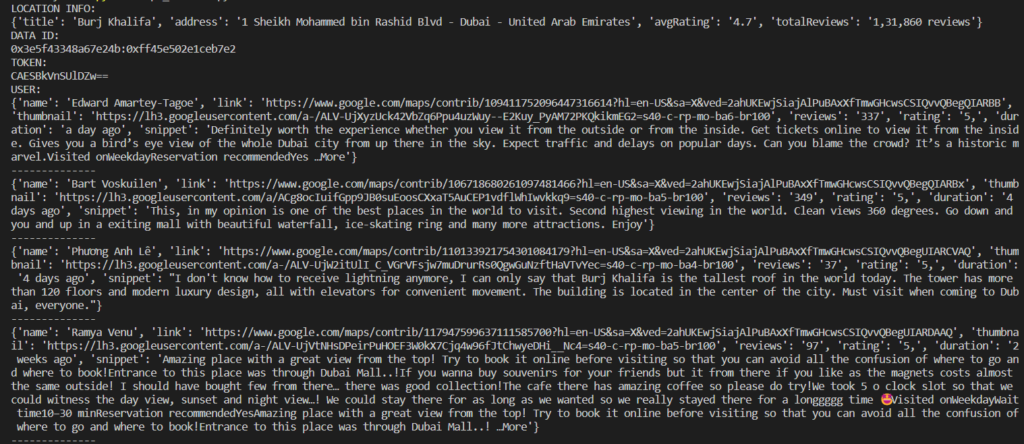
The tutorial is not over yet. I will also teach you about the extraction of the next-page reviews.
In the output of the above code, we have got the token - CAESBkVnSUlDZw==
Let us embed this in our URL:
https://www.google.com/async/reviewDialog?hl=en_us&async=feature_id:0x3e5f43348a67e24b:0xff45e502e1ceb7e2,next_page_token:CAESBkVnSUlDZw==,sort_by:qualityScore,start_index:,associated_topic:,_fmt:pc
Make an HTTP request with this URL in your code. You will get the following page reviews successfully.
Exporting Google Maps Reviews Data To CSV
Once you scrape the reviews, push the code below after the for loop into your scraper to save the reviews in a CSV file.
with open("reviews_data.csv", "w", newline="", encoding="utf-8") as csvfile:
fieldnames = ['name', 'link', 'thumbnail', 'reviews', 'rating', 'duration', 'snippet']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for review in reviews_results:
writer.writerow(review)
print("Data saved to reviews_data.csv")
Don’t forget to import the CSV library before running the program.
import csv
This will return you the following CSV file containing reviews of that particular location.
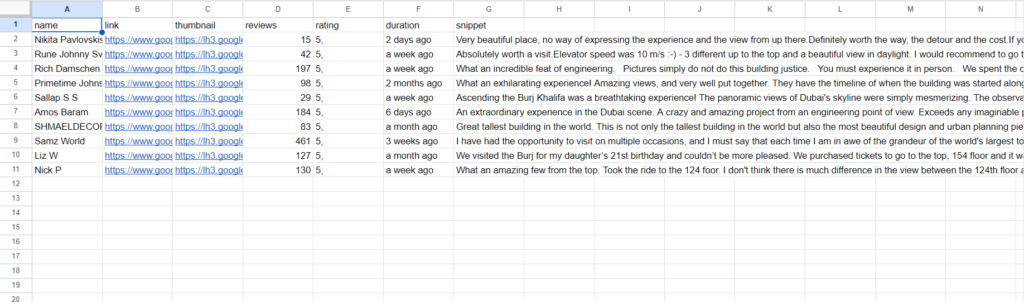
Using Google Maps Reviews API To Scrape Google Reviews
Scraping Google Maps Reviews can be challenging. Many developers can’t deal with the frequent proxy bans and CAPTCHAs restricting access to this valuable data. However, Serpdog’s Google Maps Reviews API offers a fully user-friendly and streamlined solution, ensuring consistent 24×7 uninterrupted data access for scraping reviews from Google.

To use our API, you need to sign up on our website. It will only take a bit.
Once you are registered, you will be redirected to a dashboard. There, you will get your API Key.
Use this API Key in the below code to scrape reviews from Google:
import requests
payload = {'api_key': 'APIKEY', 'data_id': '0x89c25090129c363d:0x40c6a5770d25022b'}
resp = requests.get('https://api.serpdog.io/reviews', params=payload)
print (resp.text)
The above Python code will help you extract the following data, including user information, rating, review, etc. Here is the output you will receive:
"reviews": [
{
"user": {
"name": "Vo Kien Thanh",
"link": "https://www.google.com/maps/contrib/106465550436934504158?hl=en-US&sa=X&ved=2ahUKEwj7zY_J4cv4AhUID0QIHZCtC0cQvvQBegQIARAZ",
"thumbnail": "https://lh3.googleusercontent.com/a/AATXAJxv5_uPnmyIeoARlf7gMWCduHV1cNI20UnwPicE=s40-c-c0x00000000-cc-rp-mo-ba4-br100",
"localGuide": true,
"reviews": "111",
"photos": "329"
},
"rating": "Rated 5.0 out of 5,",
"duration": "5 months ago",
"snippet": "The icon of the U.S. 🗽🇺🇸. This is a must-see for everyone who visits New York City, you would never want to miss it.There’s only one cruise line that is allowed to enter the Liberty Island and Ellis Island, which is Statue Cruises. You can purchase tickets at the Battery Park but I’d recommend you purchase it in advance. For $23/adult it’s actually very reasonably priced. Make sure you go early because you will have to go through security at the port. Also take a look at the departure schedule available on the website to plan your trip accordingly.As for the Statue of Liberty, it was my first time seeing it in person so what I could say was a wow. It was absolutely amazing to see this monument. I also purchased the pedestal access so it was pretty cool to see the inside of the statue. They’re not doing the Crown Access due to Covid-19 concerns, but I hope it will be resumed soon.There are a gift shop, a cafeteria and a museum on the island. I would say it takes around 2-3 hours to do everything here because you would want to take as many photos as possible.I absolutely loved it here and I can’t wait to come back.The icon of the U.S. 🗽🇺🇸. This is a must-see for everyone who visits New York City, you would never want to miss it. …More",
"visited": "",
"likes": "91",
"images": [
"https://lh5.googleusercontent.com/p/AF1QipPOBhJtq17DAc9_ZTBnN2X4Nn-EwIEet61Y9JQo=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipPZ2ut1I7LnECqEB2vzrBk-PSXzBxaHEE4S54lk=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipM8nIogBhwcL-dUrd7KaIxZcc_SA6YnJpp50R0C=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipPQ-YP7uw_gHTNb1gGZSGRGRrzLMzOrvh98AmSN=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipOTqBzK30vQZi9lfuhpk5329bnx-twzgIVjwcI1=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipN0TWUE35ajoTdSKelspuUpK-ZTXlRRR9SfPbTa=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipPQH_4HtdXmSdkCiDTv2jO30LksCxpe9KQI4YKw=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipN_OfX2TgXVNry5fli5v-yExbyTAfV4K7SEy3T0=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipNWKl0TeBmnzMaR_W4-7skitDwHjjJxPePbiSyd=w100-h100-p-n-k-no"
]
},
.....
]
Conclusion
In this tutorial, we learned to Scrape Google Maps Reviews Using Python. Please do not hesitate to message me if I missed something. If you think we can complete your custom scraping projects, you can contact us.
Follow me on Twitter. Thanks for reading!