
Access to real-time news search results is crucial for businesses to discover the latest headlines and updates regarding their brand enabling them to stay informed about the sentiments of the public and media houses and maintain a good reputation to gain a competitive edge in the market.
Python, one of the most popular languages for web scraping, can be used for creating automated web scrapers to extract the precious data available on the internet for various purposes like Data analysis, SEO monitoring, news, and media monitoring. In this tutorial, we will use its capability to extract data from Google News Results.
What’s the Purpose of Scraping Google News?
Access to Google News Data can provide you with several benefits, including:
Brand Monitoring — News results can help you monitor the media and public perspective about your brand. It helps to keep a check on any issue or negative publicity about your company that can affect your business.
Keeps You Updated — News Results keep you updated about the current political events worldwide. It also helps you to keep a check on the current advancements taking place in your areas of interest.
Market Research — Google News Results can help you study various historical trends in your industry and the data can also be used for research-based purposes like consumer sentiment, competitor analysis, etc.
Competitor Analysis — You can utilize the news data to monitor your competitor’s latest developments and product launches. You can also study their media strategy to identify any loopholes in your tactics while dealing with media marketing.
Building Awareness – It can also be used to create public awareness on topics such as political science, GK, economics, etc.
Scraping Google News via API
We will be discussing two ways of extracting news from Google:
- Using Serpdog’s Google News API
- Using Python and Beautiful Soup
For large-scale scraping and to avoid any inconvenience it is recommended to use Google News API which will handle all the issues of CAPTCHAs and blockages at the backend by rotating millions of residential and data center proxies with different headers for each request.
Additionally, businesses can process the data faster by using the News API as it returns the response in structured JSON format bypassing the need of parsing the ugly HTML.
To use this API we need to first register on Serpdog’s website to get the API credentials.
Getting API Credentials From Serpdog’s Google News API
Registering on Serpdog is quite simple. Navigate to their Google News API product page, and click the “Get started free” button to complete the signup process.
After completing the registration process, you will be redirected to the dashboard where you will get your API Key.
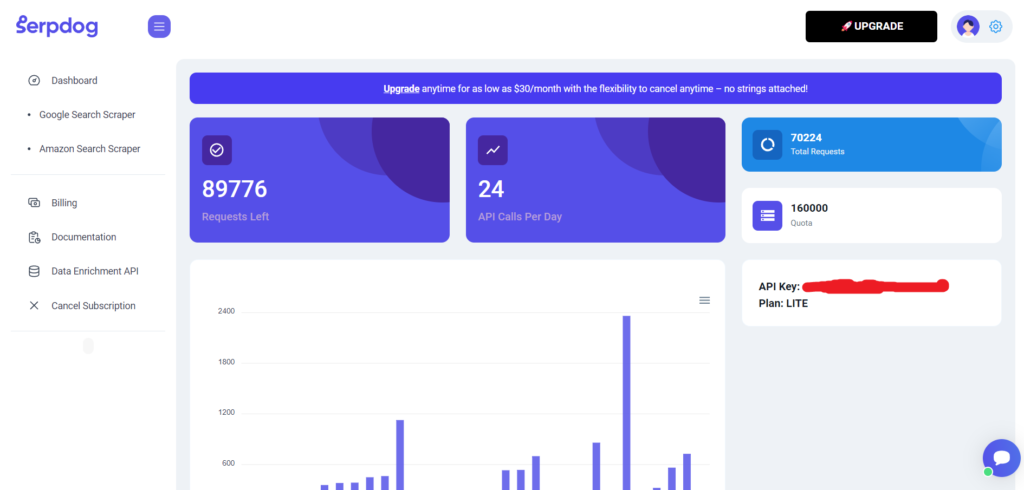
Copy this API Key and store it in a safer place as we will be needing this in the tutorial in a bit.
Setting Up our code for scraping news results
We will be installing these two libraries for this project:
- Beautiful Soup — Used for parsing the raw HTML data.
- Requests — Used for making HTTP requests.
Or you can directly install these libraries by running the below commands in your terminal:
pip install requests
pip install beautifulsoup4
Then, create a new file in your project directory and import the installed libraries.
import requests
from bs4 import BeautifulSoup
Afterward, we will initialize our API URL to get news results for the topic “stock market”.
payload = {'api_key': 'APIKEY', 'q':'stock+market' , 'gl':'us'}
resp = requests.get('https://api.serpdog.io/news', params=payload)
print (resp.text)
If you wish to implement additional parameters in the API request, you can refer to this documentation with a precise explanation of the parameters offered by Google to refine the search results.
Let us now run this program and check the discussions around the stock market in the media world.
{
"meta": {
"api_key": "APIKEY",
"q": "stock market",
"gl": "us"
},
"news_results": [
{
"title": "Dow tumbles 300 points to close out losing April as Fed decision looms: Live updates",
"snippet": "Sticky inflation data and poor earnings sent stock prices lower on the final day of a weak April.",
"source": "CNBC",
"lastUpdated": "LIVE8 minutes ago",
"url": "https://www.cnbc.com/2024/04/29/stock-market-today-live-updates.html",
"imgSrc": "data:image/jpeg;base64,/9j/4AAQSkZJRg.........................................................."
......
So, we received the meta information which consists of the parameters passed with the API request, and the news results array having all the the data about the individual news result.
You can also directly play with the news_results array by specifically targeting it using the below code.
data = resp.json()
print(data["news_results"])
Export scraped data to a CSV
The next thing we will do is to save the obtained data through the API in a CSV file. For this purpose, we are going to use the CSV library in Python which will allow us to target every data point and store it in a safer place.
import requests
import csv
payload = {'api_key': 'APIKEY', 'q':'stock+market' , 'gl':'us'}
resp = requests.get('https://api.serpdog.io/news', params=payload)
data = resp.json()
with open('news_results.csv', 'w', newline='') as csvfile:
csv_writer = csv.writer(csvfile)
# Write the headers
csv_writer.writerow(["title", "snippet", "source", "lastUpdated", "url"])
# Write the data
for result in data["news_results"]:
csv_writer.writerow([result["title"], result["snippet"], result["source"], result["lastUpdated"], result["url"]])
print('Done writing to CSV file.')
Run this program and check your project folder for the file named news_results.csv.
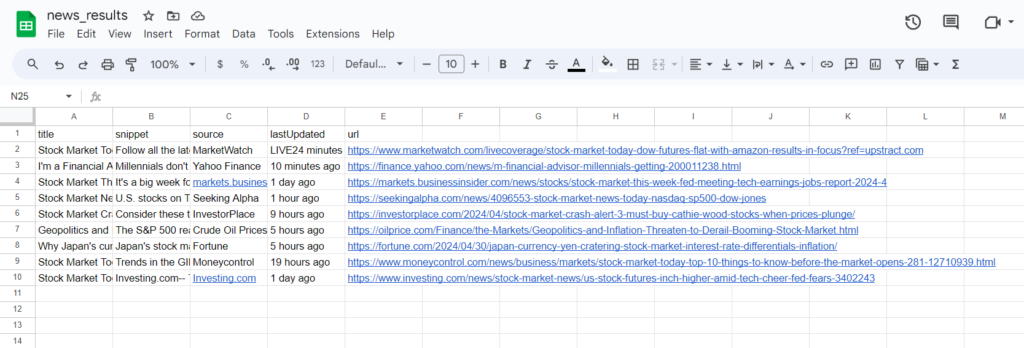
Scraping Google News Using Python and BS4
In this blog post, we’ll create a Python script to extract the first 100 Google News results including, the title, description, link, source, and date.
Process
Before starting, I assume you have set up your Python project on your device. So, open the project file in your respective code editor and import these two libraries, which we will use in this tutorial.
import json
import requests
from bs4 import BeautifulSoup
Now, let’s create a function to scrape the Google News Results:
def getNewsData():
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
response = requests.get(
"https://www.google.com/search?q=amazon&gl=us&tbm=nws&num=100", headers=headers
)
soup = BeautifulSoup(response.content, "html.parser")
news_results = []
First, we set the header to the User Agent, which will help us to make our scraping bot make an organic visit to Google. Then we made an HTTP request on the target URL using the request library we imported above and stored the extracted HTML in the response variable. In the last line, we created an instance of the BeautifulSoup library to parse the HTML data.
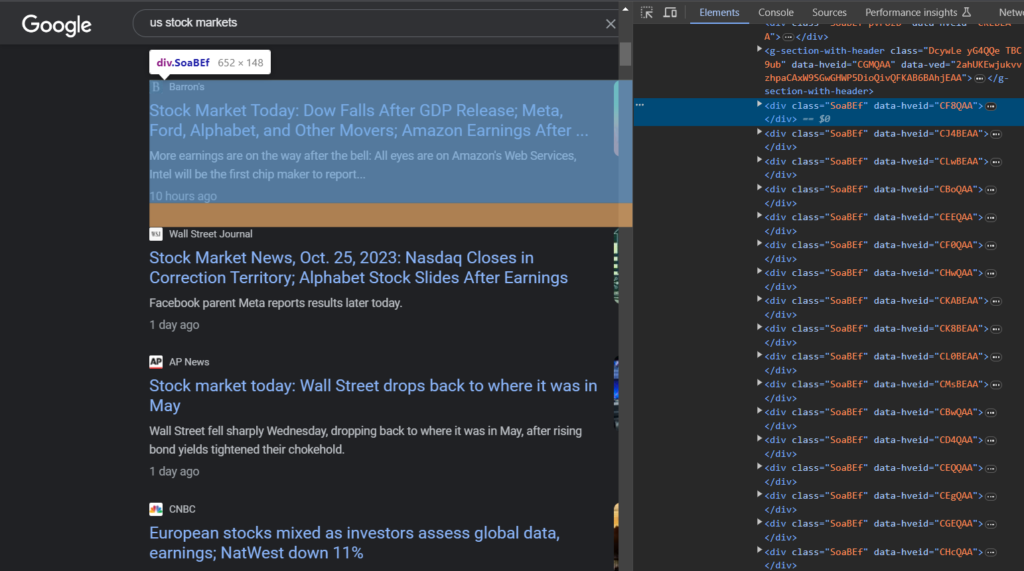
Let us now search for the tags from the HTML to extract the required data.
If you inspect the HTML file, you will find every result or news article is contained inside this div.SoaBEf tag. So, we will loop every div container with the class SoaBEf to get the required data.
for el in soup.select("div.SoaBEf"):
news_results.append(
{
}
)
print(json.dumps(news_results, indent=2))
getNewsData()
Then, we will find and locate the tags and classes for the entities that we need to scrape in this tutorial.
Scraping News Title
Let’s find the headline of the news article by inspecting it.

As you can see in the above image, the title is under the div container with the class MBeuO.
Add the following code in the append block to get the news title.
"title": el.select_one("div.MBeuO").get_text(),
Scraping News Source and Link
Similarly, we can extract the News source and link from the HTML.
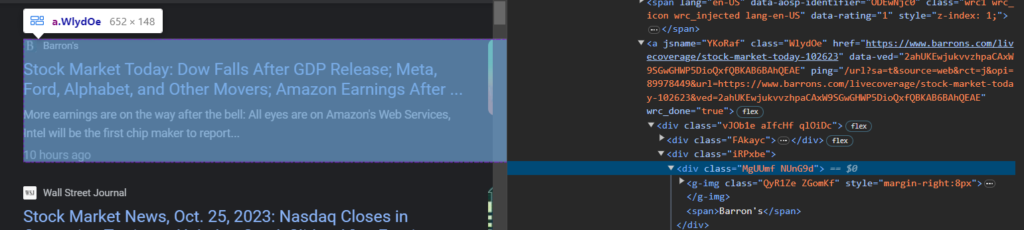
The news link is present as the value of the href attribute of the anchor link, and the source is contained inside the div tag with the class NUnG9d. You can scrape both the source and link using the following code.
"source": el.select_one(".NUnG9d span").get_text(),
"link": el.find("a")["href"],
Scraping News Description and Date
The news description is stored inside the div tag with class GI74Re, and the date is present inside the div tag with the class LfVVr.

Copy the following code to extract both of them.
"snippet": el.select_one(".GI74Re").get_text(),
"date": el.select_one(".LfVVr").get_text(),
Finally, we are done with extracting all the entities.
Complete Code
So, this is how you can scrape Google News results. If you want to extract more information from the HTML, you can make custom changes to your code accordingly. For the current situation, here is the complete code:
import json
import requests
from bs4 import BeautifulSoup
def getNewsData():
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
response = requests.get(
"https://www.google.com/search?q=us+stock+markets&gl=us&tbm=nws&num=100", headers=headers
)
soup = BeautifulSoup(response.content, "html.parser")
news_results = []
for el in soup.select("div.SoaBEf"):
news_results.append(
{
"link": el.find("a")["href"],
"title": el.select_one("div.MBeuO").get_text(),
"snippet": el.select_one(".GI74Re").get_text(),
"date": el.select_one(".LfVVr").get_text(),
"source": el.select_one(".NUnG9d span").get_text()
}
)
print(json.dumps(news_results, indent=2))
getNewsData()
Okay, so let us now run this code in our terminal to see the results:
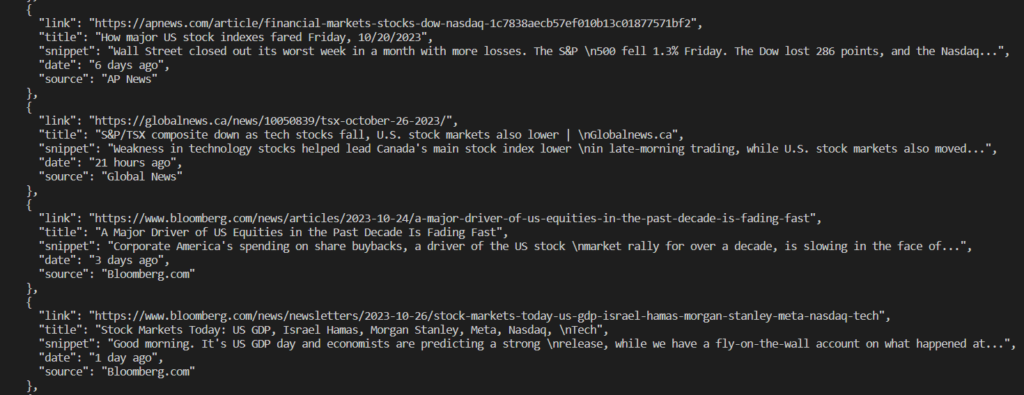
However, there is a problem. We don’t want to copy these results from top to bottom every time and generate a file to store them in a safer place. It would be much easier to store the data in a CSV file through an automated process.
First, we need to import the CSV library into our program.
import csv
Then, you can replace the print line with the following code.
with open("news_data.csv", "w", newline="") as csv_file:
fieldnames = ["link", "title", "snippet", "date", "source"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(news_results)
print("Data saved to news_data.csv")
This code will allow us to save the scraped data into a CSV file with columns link, title, snippet, date, and source.
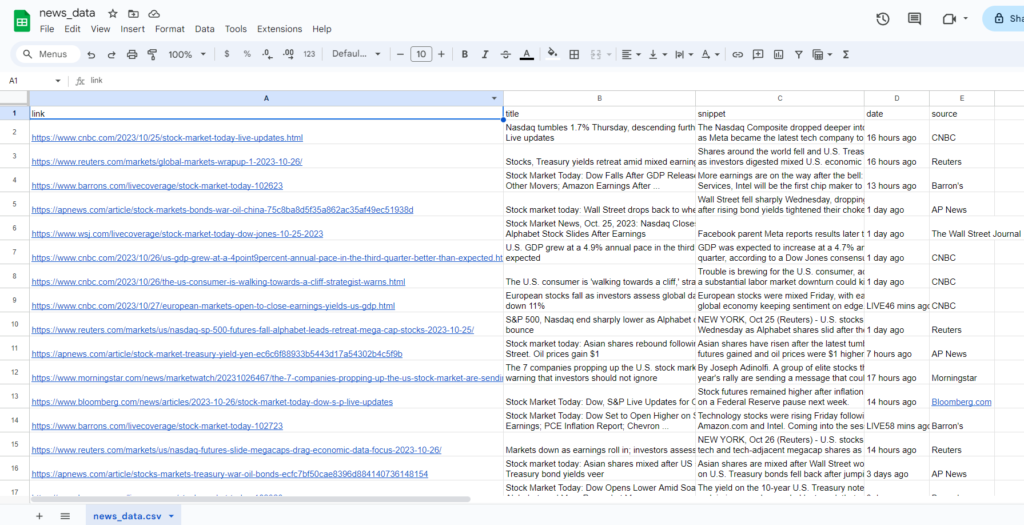
Hurray🥳🥳!!! We have successfully scraped the news data.
Conclusion:
This article discussed two ways of scraping news from Google using Python. Data collectors looking to have an independent scraper and want to maintain a certain amount of flexibility while scraping data can use Python as an alternative to interacting with the web page.
Otherwise, Google News API is a simple solution that can quickly extract and clean the raw data obtained from the web page and present it in structured JSON format.
We also learned how this extracted data can be used for various purposes, including brand monitoring and competitor analysis.
Feel free to message me anything you need clarification on. Follow me on Twitter. Thanks for reading!