

The Rust programming language was developed by Mozilla in 2010, as an alternative to C and C++. It is widely used for web and game development.
In this tutorial, we will learn web scraping Google Search Results using Rust. This language has gained little popularity, but due to its speed, and reliability, it can be used as an alternative option for other preferred web scraping languages.
This blog post will mainly focus on how to extract data from Google Search Results. We will also explore the pros and cons of the Rust programming language.
We are going to use two libraries, request and scraper, in this tutorial for scraping and parsing the raw HTML data.
By the end of this article, you will have a basic understanding of scraping Google Search Results with Rust. You can also leverage this knowledge for future web scraping projects with other programming languages.
Why Rust for scraping Google?
Rust is a high-level powerful programming language that has given a good amount of significance to its performance and concurrency. Its asynchronous programming structure allows scraping servers to handle multiple requests simultaneously, which makes it a reliable choice for handling large amounts of data and complex web scraping tasks.
Another advantage of using Rust is that it has several powerful libraries for web scraping such as reqwest that can help developers extract and process web pages easily. Also, libraries like html5ever and scraper are blazingly fast when it comes to HTML parsing.
Overall, Rust can be an efficient choice for not only scraping Google but also for other web scraping tasks, which is only possible due to its insane emphasis on performance and its robust system of libraries.
Scraping Google Search Results With Rust
Scraping Google Search Results With Rust is pretty easy. We will extract the first page results from Google, consisting of the title, link, and description. I must say, it will take a while for beginners to get used to Rust syntax. But yeah, practice makes you better!
The scraping would be in two parts:
- Fetching the raw HTML.
- HTML parsing to filter and get the required data.
Set-Up:
For beginners, to install Rust on your device, you can watch these videos:
Requirements:
After installing Rust successfully, you can run this command to create a Rust project folder:
cargo new project
Then, we will install two libraries that we will use in this tutorial.
reqwest— It will be used for making HTTP requests at the target URL.scraper— It will be used for selecting the HTML elements and parsing the extracted HTML data.
You can add these libraries to your cargo.toml file like this:
[dependencies]
reqwest = { version = “0.11.14”, features = [“blocking”] }
scraper = “0.14.0”
Now, these libraries are finally accessible in the src/main.rs file.
Process:
So, we are done with the setup. You can open your project file in your editor and write the below code to import both the required crates:
use reqwest::blocking::Client;
use scraper::{Html, Selector};
Then, we will create the main function to extract the results.
fn main() -> Result<(), Box<dyn std::error::Error>>
{
let client = Client::new();
let query = "rust+programming+language"
let url = format!(“https://www.google.com/search?q={}" , query);
let res = client.get(&url).send()?;
let html = res.text()?;
Step-by-step explanation:
- After creating the function, we created an instance of the
Clientstruct from thereqwestcrate to make HTTP requests. - Then, we create a string
queryand set it to “rust programming language”, which we will pass in the below-formatted stringurl. - In the next line, we made a connection with the URL by sending an HTTP request.
- After that, we try to get the HTML content returned from the HTTP request.
let fragment = Html::parse_document(&html);
Now, with the help of Html object from the scraper crate, we convert the extracted HTML into a document object model.
Then, with the help of a Selector object from the scraper crate, we will select all the matching div with the class name g.
let selector = Selector::parse("div.g").unwrap();
If you inspect the Google Search Page, you will get to know that every organic result is inside the div with class g.
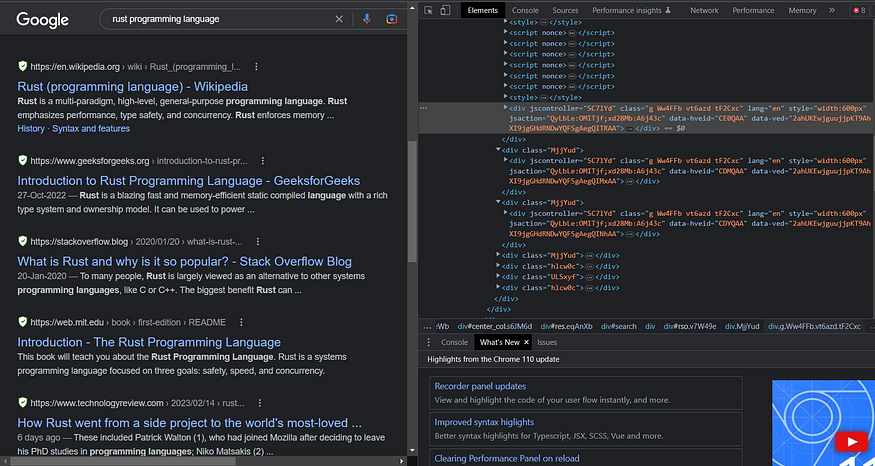
Let us now iterate over all these selected divs to get the required search data.
for element in fragment.select(&selector) {
let title_selector = Selector::parse("h3").unwrap();
let title_element = element.select(&title_selector).next().unwrap();
let title = title_element.text().collect::<Vec<_>>().join("");
let link_selector = Selector::parse(".yuRUbf > a").unwrap();
let link_element = element.select(&link_selector).next().unwrap();
let link = link_element.value().attr("href").unwrap();
let snippet_selector = Selector::parse(".VwiC3b").unwrap();
let snippet_element = element.select(&snippet_selector).next().unwrap();
let snippet = snippet_element.text().collect::<Vec<_>>().join("");
println!("Title: {}", title);
println!("Link: {}", link);
println!("Snippet: {}", snippet);
}
Ok(())
}
After creating a new Selector object for the h3 tag, we will select the first title that matches this selector from the element variable and extract the text content inside it. Then, we set the title to the text content inside our title_element.
We have followed the same process for the link and snippet, but a little difference in the link is we have extracted the href attribute of the anchor(represented by a in the code) tag.
You can find the tags for the title, link, and description under the container div.g.
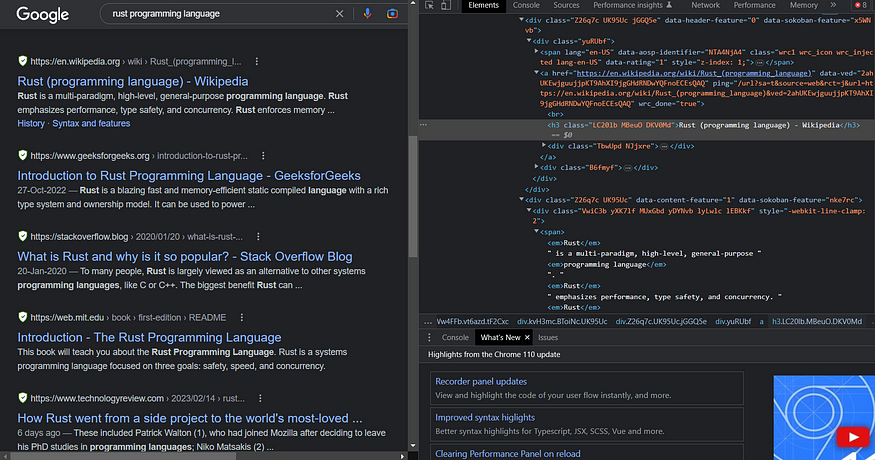
After running the code successfully, your results should look like this:
Title: Rust Programming Language
Link: https://www.rust-lang.org/
Snippet: Rust has great documentation, a friendly compiler with useful error messages, and top-notch tooling — an integrated package manager and build tool, smart multi- ...
Title: Rust (programming language) - Wikipedia
Link: https://en.wikipedia.org/wiki/Rust_(programming_language)
Snippet: Rust is a multi-paradigm systems programming language focused on safety, especially safe concurrency.
Title: Introduction to Rust Programming Language - GeeksforGeeks
Link: https://www.geeksforgeeks.org/introduction-to-rust-programming-language/
Snippet: Rust is a blazing fast and memory-efficient static compiled language with a rich type system and ownership model. It can be used to power ...
So, this is the fundamental way of scraping Google Search results with Rust.
This solution is not suggested for mass scraping, as it can result in your IP block. But, if you want to consider a more hassle-free and streamlined solution, you can try this Google SERP API to scrape Google Search Results. Serpdog rotates millions of residential proxies on its end so that its users can scrape Google peacefully without encountering any blockage or CAPTCHAs.
Benefits of Using Rust
1. Rust can handle a large amount of data thanks to its robust concurrency model.
2. Extreme level of performance by Rust makes it a popular choice for game development, system-level programming, and other intensive applications.
3. It supports reverse compatibility, allowing it to run older code even on the latest versions of the language.
Disadvantages Of Using Rust
1. The code can be challenging to understand for beginners because of the complex syntax.
2. Community support has not grown much, so the developer has to struggle even more to solve a small error.
Conclusion
In this tutorial, we learned to scrape Google Search Results with Rust. We also learned some benefits and disadvantages of using Rust.
Please do not hesitate to message me if I missed something. If you think we can complete your custom scraping projects, feel free to contact us.
Follow me on Twitter. Thanks for reading!