
We are generating an estimated 328.77 million terabytes of data each day(source). Still, 90% of this daily generated data is unstructured, which makes it inaccessible for further purposes. Web Scraping is the technique of extracting publicly available data from various sources. This technique can be utilized to convert unstructured and in-accessible data into ready-to-use for enterprises.
Web Parsing is an essential component of web scraping. It is the process of analyzing the HTML and XML documents to get refined information. There are several HTML parsers made available by the prestigious community of Python. One such extreme performance library is BeautifulSoup, which can effectively navigate through the HTML structure and return data from the HTML elements and attributes.
However, Python also offers an inbuilt functionality of matching a text pattern, known as Regex. Regular Expression or Regex is a sequence of characters used to match specific parameters within the body of text.
In this article, we will learn how to use regex to parse HTML with Python. We will also explore the benefits and drawbacks of using Regex for parsing raw HTML data.
How To Use Regex
Regex is a built-in library by Python, so there is no need to install this explicitly. Let me show you first a simple demonstration of using Regex with Python, and then we will scrape a website using the Python requests module and parse it using Regex in the next section.
Consider the sentence below. We will replace all the repetitions of the word “Peter” with “John”.
Peter Piper picked a peck of pickled peppers.<br>A peck of pickled peppers Peter Piper picked.
Copy the following code to perform this task.
import re
sentence = "Peter Piper picked a peck of pickled peppers. A peck of pickled peppers Peter Piper picked."
# Replace "Peter" with "John" using regex
new_sentence = re.sub(r'\bPeter\b', 'John', sentence)
print(new_sentence)
After importing the regex library, we initialized our sentence variable and then using re.sub(), we performed the needed replacement.
Now, you will be thinking about what r’\bPeter\b’ meant in the above code. Let me explain:
- The
rcharacter before the string denotes a raw string in Python. It’s used to prevent the backslashes within the string from being treated as escape characters. \bis the boundary character. It is used to match a position between the word and nonword character. We have implemented this twice before and after Peter to ensure that “Peter” is matched as a whole word.
Then, we gave the re.sub() function a replacement for the word “Peter”, which is “John” here. Finally, we stored the updated sentence in the new_sentence variable with no occurrence of the word “Peter”.
The output should look this:
John Piper picked a peck of pickled peppers.
A peck of pickled peppers John Piper picked.
Implementation of HTML Parsing With Regex
Requirements
In this section, we will attempt to scrape the target website using the Requests library of Python and then parse the required information with the help of Regex.
Before starting, please install the following library to begin with the project.
- Requests —Used to extract the HTML data from the target website or URL.
You can also run the following command in your project terminal to install it directly.
pip install requests
Here are the following data points which we will scrape from the target website:
- Title of the product
- Pricing of the product
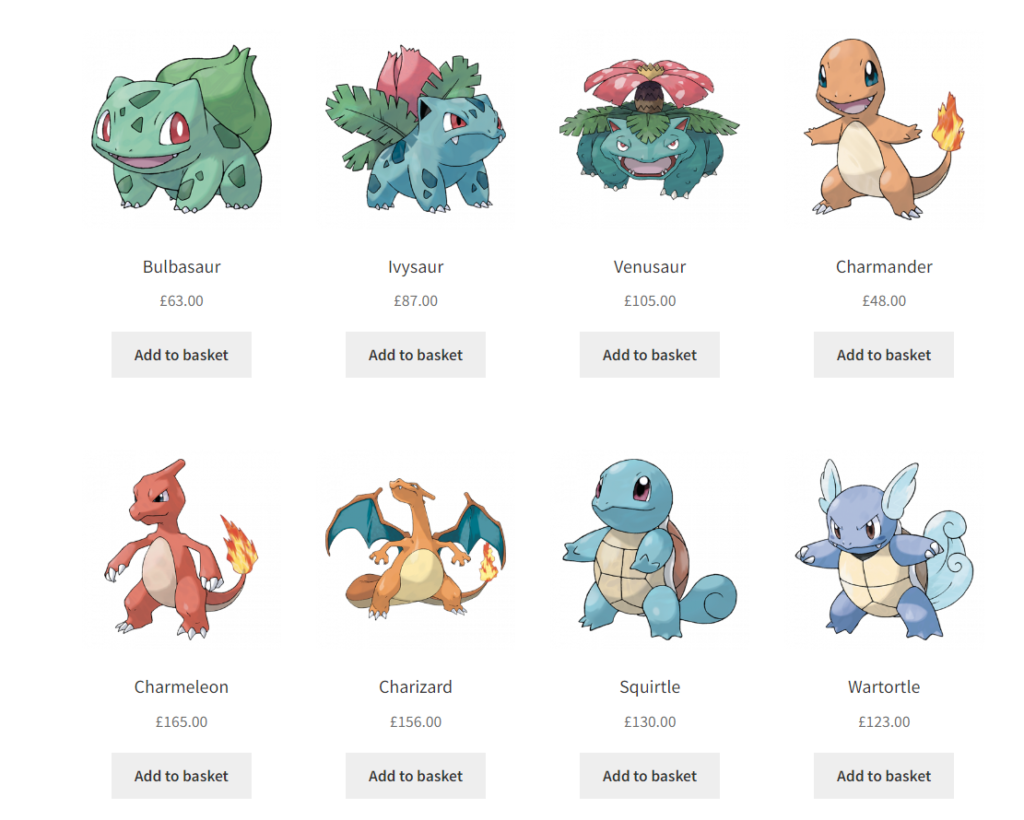
Extracting and Parsing the Data With Requests and Regex
Now, we will create an HTTP GET connection with the target URL to extract the raw HTML data.
import requests
import re
l=list()
obj={}
resp = requests.get("https://scrapeme.live/shop/").text
First, we imported the Requests and the Regex library, and then we initialized our variables in which we will store the refined data. Then, using the Requests library, we made an HTTP GET request on the URL and stored the response in resp variable.
Next, our goal is to locate the title from the HTML and create a regex pattern to extract all the product names.
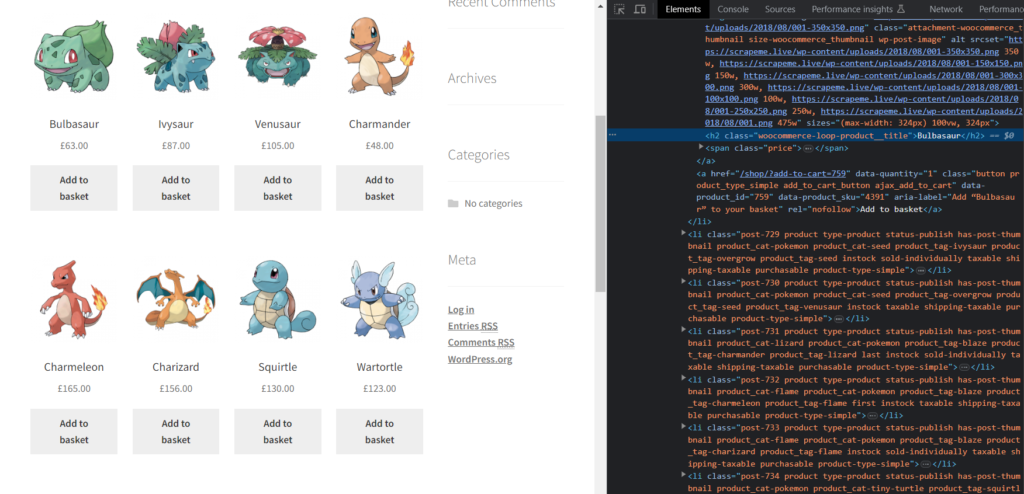
As you can see, the title is contained inside the h2 tag with the class woocommerce-loop-product__title. So, we can use the following regex pattern to extract all the titles from HTML.
pattern1 = r'<h2 class="woocommerce-loop-product__title">(.*?)</h2>'
The <h2 is what defines the opening tag of an HTML h2 element. We also used its class value in the regex pattern to match it completely. After that, we used (.*?) a lazy quantifier to match any content present inside the h2 element. Finally, we used the </h2> to match the closing part of the HTML h2 element.
Let us now find the location of the pricing tag in HTML.
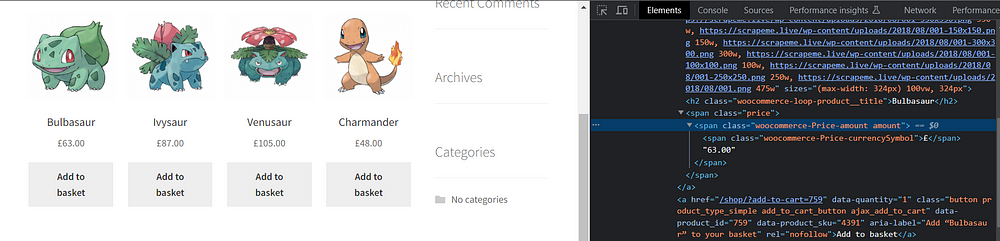
So, the pricing is present in the span tag with the class price. It’s regex pattern should look this:
pattern2 = r'<span class="price"><span class="woocommerce-Price-amount amount">(.*?)(\d+\.\d+)</span>'
Step-by-step explanation:
- The
<span class="price">matches the beginning of the span tag with the class price. <span class=”woocommerce-Price-amount amount”>: This part matches the opening<span>tag with two class attributes,woocommerce-Price-amountandamount.(.*?): This part defines a non-capturing group that matches any content before the numerical price.- Then, we used a capturing group
(\d+\.\d+)that matches any number of digits before and after the decimal part. - Finally, we used the
</span>to match the closing part of the span element of HTML.
We are capturing two groups for pricing. The first one consists of the pound symbol, and the second one contains the actual pricing. If you use the findAll method and print its values using a for loop, you will get to know that it returns a list of two values.
prices = re.findall(pattern2, resp)
for i in range(len(prices)):
print(prices[i])
The output will look like this:
('<span class="woocommerce-Price-currencySymbol">£</span>', '63.00')
('<span class="woocommerce-Price-currencySymbol">£</span>', '87.00')
('<span class="woocommerce-Price-currencySymbol">£</span>', '105.00')
But, we have to extract only the second part, so the correct way of parsing the title and pricing both will look like this:
for i in range(len(titles)):
obj["Title"]=titles[i]
obj["Price"]=prices[i][1]
l.append(obj)
obj={}
print(l)
Complete Code
For practice, you can also extract product links, images, and other relevant data. But for now, our code will look like this:
import requests
import re
l=list()
obj={}
resp = requests.get("https://scrapeme.live/shop/").text
pattern1 = r'<h2 class="woocommerce-loop-product__title">(.*?)</h2>'
pattern2 = r'<span class="price"><span class="woocommerce-Price-amount amount">(.*?)(\d+\.\d+)</span>'
titles = re.findall(pattern1, resp)
prices = re.findall(pattern2, resp)
for i in range(len(titles)):
obj["Title"]=titles[i]
obj["Price"]=prices[i][1]
l.append(obj)
obj={}
print(l)
Pros and Cons of Using Regex
Regex comes with numerous benefits, some of which are:
- It works rapidly and helps in improving the latency rate of the scraper.
- It is incredibly flexible and can easily and efficiently process and clean complex data sets.
- It is highly useful when extracting data entities like email addresses, phone numbers, etc.
However, there are also some cons associated with it:
- The patterns can be challenging to maintain and understand.
- Regex patterns are fragile and can fail even on small changes in the pattern.
- Slight variations in the text can be difficult to adapt.
Conclusion
Regex is a valuable tool for parsing and text-processing tasks. However, it’s essential to consistently test and maintain these patterns depending on various input scenarios. While it can be useful in some cases, due to its limitations, it is advisable to use HTML parsers like BeautifulSoup, which are helpful in the majority of use cases.
I hope this tutorial gave you a basic overview of parsing HTML data using Regex.
If you think we can complete your web scraping tasks and help you collect data, please don’t hesitate to contact us.
Please do not hesitate to message me if I missed something. Follow me on Twitter. Thanks for reading!
Additional Resources
I have prepared a complete list of blogs to learn web scraping that can give you an idea and help you in your web scraping journey.