
Amazon is at present king of the e-commerce industry. With more than 2 billion of traffic clocking to its website per month, it not only shows its complete market domination but also establishes itself as a data-rich website for data miners.
As of 2022 data, more than 353 million products were listed on Amazon(source), which makes it a lucrative website for price monitoring and data analysis.
In this blog, we will learn to scrape product information from Amazon using Python and its libraries. We will also explore the benefits of extracting data from Amazon, including price monitoring, market trends, and gaining crucial information for data-driven decisions.
Why scrape Amazon?
Scraping Amazon can provide you with various benefits:
Price Monitoring — Scraping Amazon allows you to monitor the pricing of a specific product from multiple online vendors, which not only helps consumers save money but also saves their time instead of checking the pricing manually on numerous websites.
Restock Notification — Retailers can use Amazon Product Data to check for product availability on the e-commerce website, enabling timely restock notifications and efficient inventory management.
Build a Product Database — Product data from Amazon can also be used to enrich datasets and create a repository of your own according to your needs and requirements.
Read More: Web Scraping For Price Monitoring
Let’s begin scraping Amazon
Scraping Amazon using Python is not as difficult as it may seem. Let us first begin with the set-up of our project.
Set-up
For those users who have not installed Python on their devices, please consider these videos:
If you don’t want to watch videos, you can directly install Python from their official website.
Now, open your respective code editor. In the terminal, write the below command.
mkdir amazonscraper
This will create a folder named as amazonscraper for our project.
Now, let’s install the necessary libraries for this project in our folder.
- Beautiful Soup — A powerful third-party library for parsing raw HTML data.
- Requests — A powerful third-party library for extracting the raw HTML data from the web page.
If you don’t want to read their documentation, install these two libraries by running the below commands.
pip install requests
pip install beautifulsoup4
Next, create a new file in your project folder where we will write all our code.
Scraping the Amazon.com Product Page
Let’s extract the Amazon Product page with the help of a requests library. Open up your project file and type the following code:
import requests
url = "https://www.amazon.com/SAMSUNG-Factory-Unlocked-Smartphone-Lavender/dp/B0BLP1HYDS"
html = requests.get(url)
print(html.text)
Run this code in your terminal. You will be greeted with a special message by the Amazon anti-bot mechanism.

This is because Amazon has already detected the request made by a scraping bot rather than a human. So, the question now arises: how can you bypass that on-site protection by Amazon?
Here is the answer, if you have ever opened the network tab of the developer console while navigating to Amazon.com, you would have noticed that the browser passes certain headers to request data from the website server.
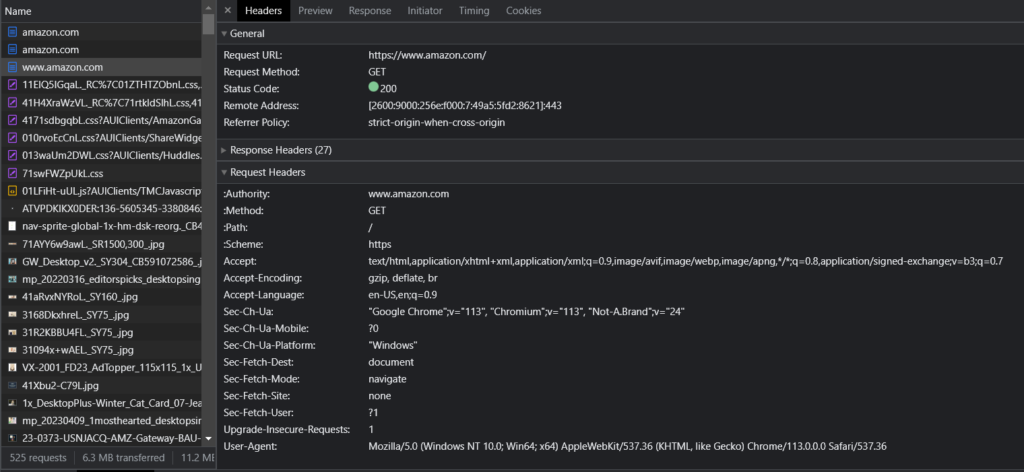
In the above image, you can see a list of request headers passed by the browser to receive the data. Let us try to add some of them in our code so we can bypass this anti-bot mechanism implemented by Amazon.
import requests
url = "https://www.amazon.com/SAMSUNG-Factory-Unlocked-Smartphone-Lavender/dp/B0BLP1HYDS"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9"
}
resp = requests.get(url, headers=headers)
print(resp.text)
Run this code in your terminal. You will successfully get the desired output.
Extracting Amazon.com Product Data
It is essential to decide in advance what data needs to be extracted. We will extract the following information from the product page:
- Name
- Price
- Rating
- Specifications
- Description
- Images

So, we are going to parse this data using the BeautifulSoup library. Although you can use other libraries like lxml, PyQuery, etc., with BS4, you can easily navigate inside the HTML using its powerful infrastructure, and get the results as quickly as possible.
We will be following a simple and streamlined process. With the developer tool in our browser, we are going to find the location of every element we want to extract.
This method can be accessed by right-clicking your mouse on the target element, which will open a menu. Choose “Inspect” from it, and you will be able to obtain the HTML location of that element.
Extracting the Product Name
Let‘s first start with parsing the product title. Just right-click on the name and click on “Inspect”.
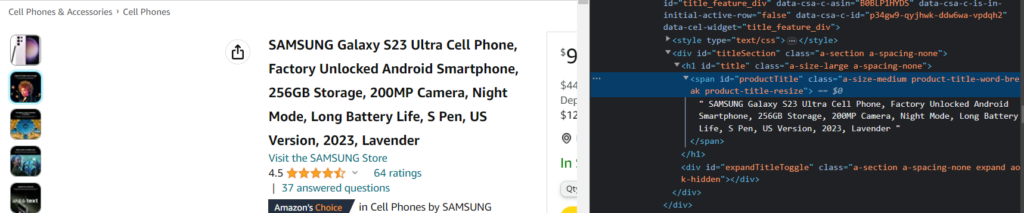
In the above image, you can see that the title is under the span tag with the id productTitle. Let’s use this tag in our code to extract the product title.
import requests
from bs4 import BeautifulSoup
url="https://www.amazon.com/SAMSUNG-Factory-Unlocked-Smartphone-Lavender/dp/B0BLP1HYDS"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9"
}
resp = requests.get(url, headers=headers)
print(resp.status_code)
soup = BeautifulSoup(resp.text,'html.parser')
title = soup.find('span',{'id':'productTitle'}).text.strip()
print(title)
After printing the status code, we created a BeautifulSoup object from the text in resp variable.
Then, we used the soup.find() method to get the first span element with the id attribute productTitle in the HTML. By using the text() method we will be able to get the text from that element, and then we will remove all trailing spaces from the extracted string using the strip() method.
Run this code, and your output should look like this:
SAMSUNG Galaxy S23 Ultra Cell Phone, Factory Unlocked Android Smartphone, 256GB Storage, 200MP Camera, Night Mode, Long Battery Life, S Pen, US Version, 2023, Lavender
Extracting the Product Pricing
Now, we will find the location of the pricing tag.
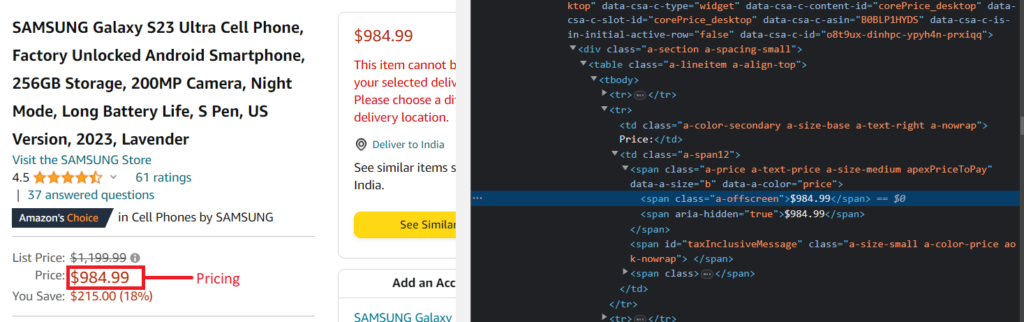
As you can see, in the above image, there are two prices in the HTML, but we will extract only one.
pricing = soup.find("span",{"class":"a-price"}).find("span").text
print(pricing)
This will give you the following output.
$999.99
Extracting the Product Rating
Scraping the product rating is a bit logical!
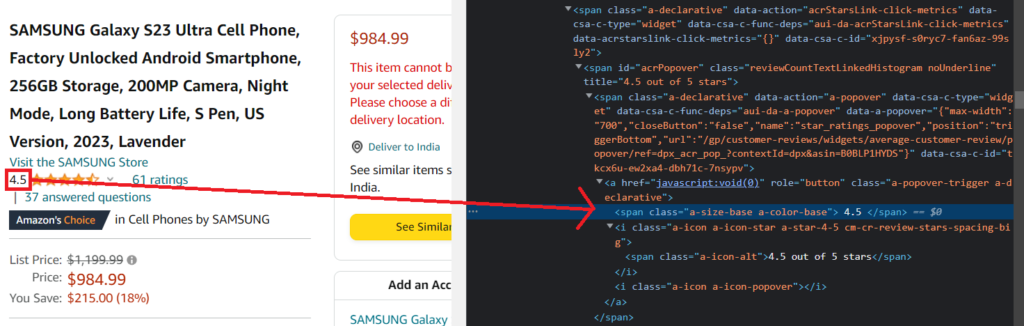
So, the product rating is present inside the span tag with the class name a-color-base which is also contained in the span tag with the id acrPopover.
rating = soup.select_one('#acrPopover .a-color-base').text.strip()
Extracting the Product Specifications
Getting product specifications is easy but requires a little more work.
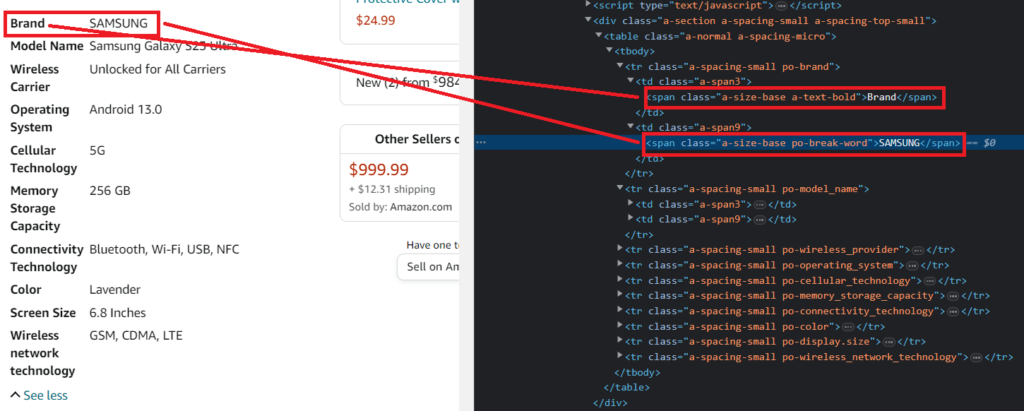
As you can see in the above image, each row is under the tr tag. The left column of product attributes is under the span tag with class a-text-bold and the right column of product values is under the span tag with class po-break-word.
specifications = {}
prodct_attrs = []
prodct_values = []
for el in soup.find_all("tr", class_="a-spacing-small"):
prodct_attrs.append(el.select_one("span.a-text-bold").text.strip())
prodct_values.append(el.select_one(".po-break-word").text.strip())
specifications = dict(zip(prodct_attrs, prodct_values))
print(specifications)
In the above code, first, we created two arrays prodct_attrs and prodct_values and then we looped over every tr tag under the table and extracted the information from both columns of product attributes and product values.
If you run this code, your output should look like this:
{
'Brand': 'SAMSUNG',
'Model Name': 'Samsung Galaxy S23 Ultra',
'Wireless Carrier': 'Unlocked for All Carriers',
'Operating System': 'Android 13.0',
'Cellular Technology': '5G',
'Memory Storage Capacity': '256 GB',
'Connectivity Technology': 'Bluetooth, Wi-Fi, USB, NFC',
'Color': 'Lavender',
'Screen Size': '6.8 Inches',
'Wireless network technology': 'GSM, CDMA, LTE'
}
Extracting the Product Description
Similarly, you can extract the product description.
product_description = soup.select_one('#productDescription').text.strip()
Extracting the Product Images
Finally, we will scrape the product images.
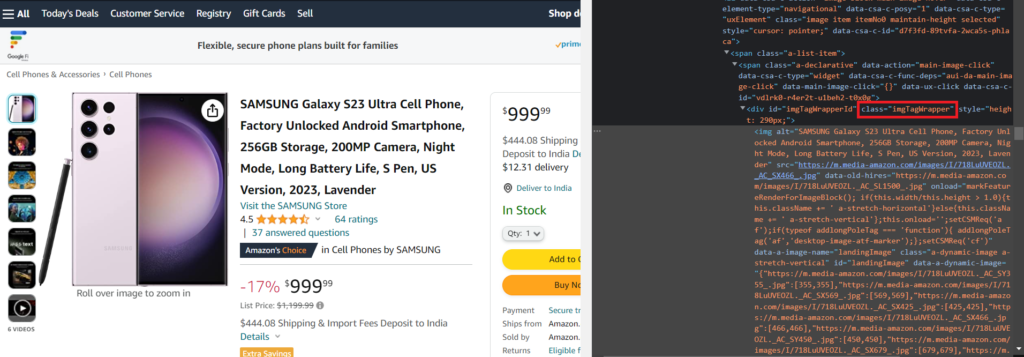
If you inspect the image, you will find that the img tag is present inside the div tag with class imgTagWrapper.
But here comes the catch! If you print the length of the array consisting of images extracted from the div tag with class imgTagWrapper, it will print 3, which is unexpected, as the total images are 6.
product_images = soup.find_all("div",{"class":"imgTagWrapper"})
print(len(product_images))
Let me tell you what is happening here. The rest of the images which we are not able to scrape are present inside the script tag of the HTML. These are loaded in the HTML body through the use of JS rendering by sending a request to the backend.
Let me explain how you can extract all those images. Just follow these instructions:
- Copy the URL of the product image.
- Then navigate to the view page source of the web page and search for that URL.
- You will find that all these images are assigned as values for the
hiReskey.
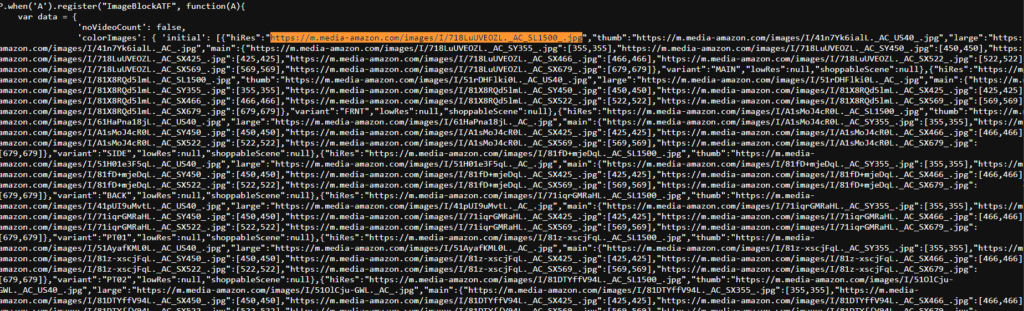
Now, we will make a regex pattern and extract all those images with the pattern “hiRes”: “URL”.
import re
images = re.findall('"hiRes":"(.+?)"', resp.text)
print(images)
Here, .+? acts as a capturing group that can match any sequence of characters.
In the above code, first, we imported the regex library and then used the re.findall() method to find all the images matching the respective pattern in the response body.
Run this code in your terminal. You will get the desired results.
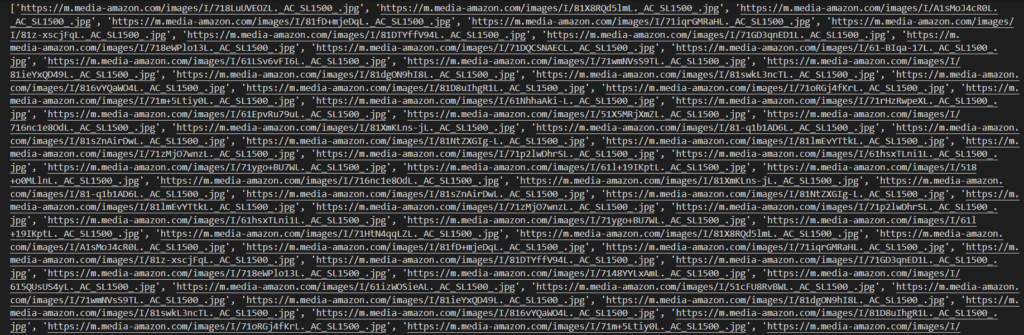
In this manner, you can also scrape more data and make changes to the script according to your needs.
Here is the complete code:
import requests
from bs4 import BeautifulSoup
import re
url = "https://www.amazon.com/SAMSUNG-Factory-Unlocked-Smartphone-Lavender/dp/B0BLP1HYDS"
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Config/94.2.7641.42",
"Accept-Language": "en-US,en;q=0.9"
}
resp = requests.get(url, headers=headers)
print(resp.status_code)
soup=BeautifulSoup(resp.text,'html.parser')
title = soup.find('span', {'id':"productTitle"}).text.strip()
pricing = soup.find("span",{"class":"a-price"}).find("span").text.strip()
rating = soup.select_one('#acrPopover .a-color-base').text.strip()
# Extract and convert the text to a float
average_rating = float(rating) if rating else None
specifications = {}
prodct_attrs = []
prodct_values = []
for el in soup.find_all("tr", class_="a-spacing-small"):
prodct_attrs.append(el.select_one("span.a-text-bold").text.strip())
prodct_values.append(el.select_one(".po-break-word").text.strip())
specifications = dict(zip(prodct_attrs, prodct_values))
product_description = soup.select_one('#productDescription').text.strip()
images = re.findall('"hiRes":"(.+?)"', resp.text)
print(images)
print(product_description)
print(specifications)
print(title)
print(pricing)
print(rating)
Using Amazon Product API To Scrape Product Data
Serpdog provides an easy and simple API solution to scrape Amazon Product Data using its powerful Amazon Scraper API. Additionally, it manages the proxies and CAPTCHAs for a smooth scraping experience, and not only provides search data but also product data including their pricing and review information.
You will also receive 1000 free requests upon signing up.
You will get an API Key after registering on our website. Embed the API Key in the code below, and you will be able to scrape Amazon Product Data at a rapid speed.
import requests
payload = {'api_key': 'APIKEY', 'domain': 'com' ,'asin':'B0BLP1HYDS'}
resp = requests.get('https://api.serpdog.io/amazon_product', params=payload)
print (resp.text)
Conclusion
In this tutorial, we learned to scrape Amazon Product Data using Python. Please do not hesitate to message me if I missed something.
If you think we can complete your custom scraping projects, feel free to contact us. Follow me on Twitter. Thanks for reading!
Additional Resources
I have prepared a complete list of blogs on web scraping, which can help you in your data extraction journey: