

R, a programming language for statistical computing, was developed by two professors from the University of Auckland, Ross Ihaka and Robert Gentleman, in 1993. S programming language was the inspiration for R. Its ease of use, backing by various libraries, and continuous improvement over the years have made it an excellent tool for web scraping.
R is a powerful language that enables it to handle various tasks without any issues, thereby increasing its robustness and effectiveness.
Web scraping and data mining have become thriving industries over the past few years. In particular, scraping websites like Google can open various opportunities for earning. Scraping Google offers several benefits, such as SERP monitoring, price monitoring, SEO, and more.
In this tutorial, we will teach you how to scrape Google Search Results with R. We will also explore some advantages and disadvantages of using R programming language.
This tutorial is designed to teach you how to fetch and handle the complex HTML structures of Google Search Results. It will help you create personal web scraping projects as you progress in your data extraction journey.
Let’s begin the tutorial!
Let’s start scraping
The first step towards scraping Google Search Results with R would be fetching the HTML data from Google webpage by passing appropriate headers and then parsing the HTML to get the desired data.
Set-Up
If you have not already installed R, you can watch these videos for the installation.
Requirements
For scraping Google search results with R, we will install a library:
- Rvest — This library will assist us in fetching and parsing the HTML data from the target website.
You can also install this library in your project folder by running the below command.
install.packages("rvest")
Process
Now that we have all the ingredients on the table, it’s time to cook our food! As mentioned in the above section, our first step would be making a GET request on the target URL. Let us now implement this!
Import the library we have installed above.
library(rvest)
After that, create a function and initialize the target URL and the respective headers to pass with the GET request.
getData <- function() {
headers <- c("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36 Unique/99.7.2776.77")
url <- "https://www.google.com/search?q=cakes+in+boston&gl=us"
User Agent is a request header that identifies the client software and can be used to make our scraping bot mimic an organic user.
Then, we will use the read_html() function to fetch the HTML from the target webpage.
response <- read_html(url, headers = headers)
After scraping the data, we will locate the required tags from the HTML.
For this, you have to inspect the search results of the target webpage.
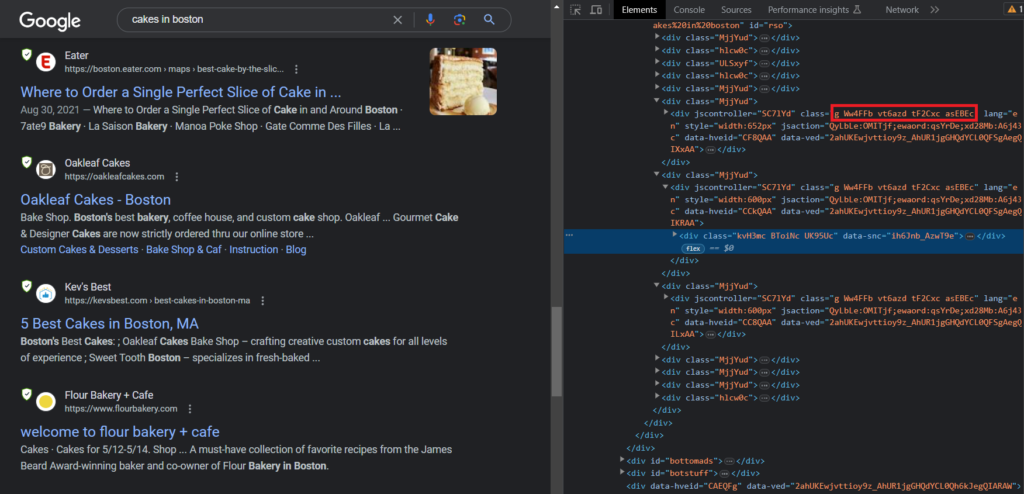
From the above image, you can derive a conclusion that every organic result comes under the div tag with class g.
This allows us to iterate over every div tag with the class g to extract the required information.
results <- html_nodes(response, "div.g")
Next, we will locate the title, link, and description inside the HTML.
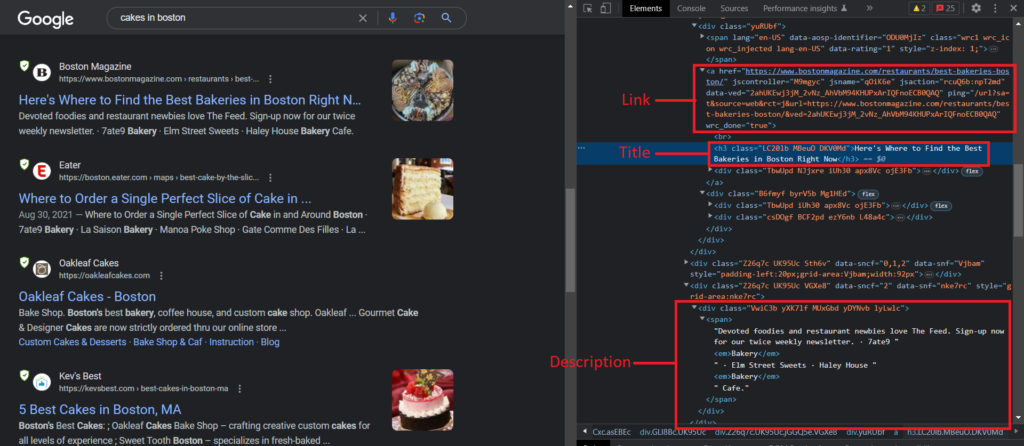
Inspect the search results again. You will observe that the link is present under the tag yuRUbf, the h3 tag represents the title of the respective organic result, and the description comes under the tag VwiC3b.
c <- 0
for (result in results) {
title <- html_text(html_nodes(result, "h3"))
link <- html_attr(html_nodes(result, ".yuRUbf > a"), "href")
description<- html_text(html_nodes(result, ".VwiC3b"))
position <- c + 1
cat("Title: ", title, "\n")
cat("Link: ", link, "\n")
cat("Description: ", description, "\n")
cat("Position: ", position, "\n\n")
c <- c + 1
}
}
getData()
In the above code, we extracted the required data step-by-step by identifying them with the help of their respective tags. We are also printing the position or rank of every organic result.
Run this code in your project terminal. You should get the following results.
Title: Where to Order the 10 Best Cakes in Boston · The Food Lens,
Link: https://www.thefoodlens.com/boston/guides/best-cakes/,
Snippet: Where to Order the 10 Best Cakes in Boston ; Weesh Bake Shop. Roslindale · Bakery · Dessert · $$$$ ; La Saison Bakery · Cambridge · $$ ; Manoa Poke ...
Position: 1
Title: Top 10 Best Birthday Cake in Boston, MA - June 2023
Link: https://www.yelp.com/search?find_desc=Birthday+Cake&find_loc=Boston%2C+MA
Snippet: Best Birthday Cake near me in Boston, Massachusetts ; Soul Cake. 7.5 mi. 16 reviews ; Jonquils Cafe & Bakery. 2.9 mi. 538 reviews ; Sweet Teez Bakery. 0.9 mi. 15 ...
Position: 2
Title: Here's Where to Find the Best Bakeries in Boston Right Now
Link: https://www.bostonmagazine.com/restaurants/best-bakeries-boston/
Snippet: Devoted foodies and restaurant newbies love The Feed. Sign-up now for our twice weekly newsletter. · 7ate9 Bakery · Elm Street Sweets · Haley House Bakery Cafe.
Position: 3
Here is the complete code:
library(rvest)
getData <- function() {
headers <- c("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36 Unique/99.7.2776.77")
url <- "https://www.google.com/search?q=cakes+in+boston&gl=us"
response <- read_html(url, headers = headers)
results <- html_nodes(response, "div.g")
c <- 0
for (result in results) {
title <- html_text(html_nodes(result, "h3"))
link <- html_attr(html_nodes(result, ".yuRUbf > a"), "href")
description<- html_text(html_nodes(result, ".VwiC3b"))
position <- c + 1
cat("Title: ", title, "\n")
cat("Link: ", link, "\n")
cat("Description: ", description, "\n")
cat("Position: ", position, "\n\n")
c <- c + 1
}
}
getData()
I believe you now understand how to scrape Google Search Results by writing a basic piece of code. You can customize the code above to retrieve more data if needed.
Scraping Google Using Using R With Serpdog
Extracting data using the above method will result in you being blocked by Google in a short period. Instead, you can utilize Serpdog’s Google Search API, which can be integrated with every major programming language, including R. This API will enable you to scrape data at scale without the risk of being blocked.
Before we start, you can also test our API from the Dashboard.
You can perform this task by signing up on Serpdog. After completing the signup part, you will land on our dashboard, where you can find the API Key on the right-hand side.
If you decide to test it from the dashboard, click on the Google Search Scraper button in the sidebar.
After clicking the button, you will be directed to a page where you need to paste your Google Search URL.
Let’s paste the URL we used in the previous section and click the “Scrape” button.
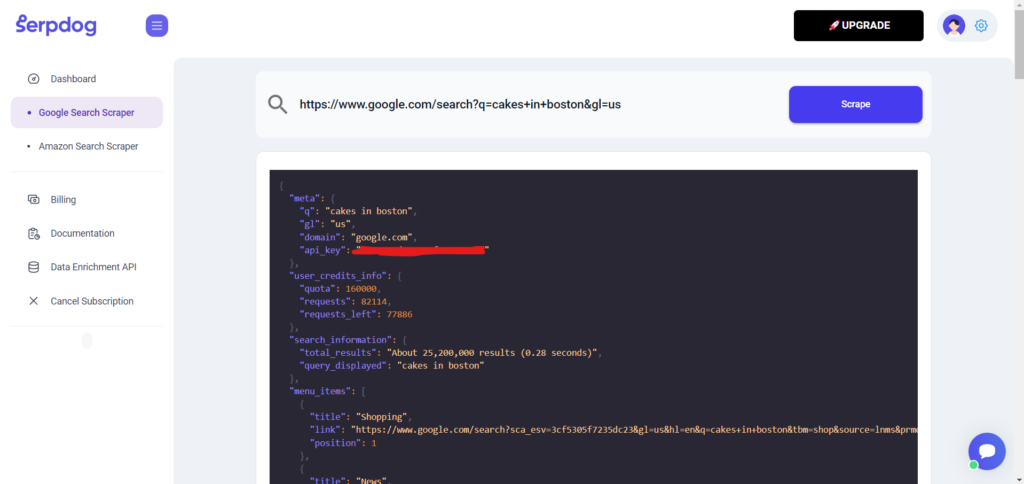
As you can see, the scraper tool has returned the search results.
Now, let’s discuss how to use Serpdog’s API with R.
The process is straightforward!
Simply copy your API Key from the dashboard and integrate it into the code provided below.
library(httr)
url <- "https://api.serpdog.io/search?api_key=APIKEY&q=cakes+in+boston&gl=us"
response <- GET(url, config(ssl_verifypeer = 0L, ssl_verifyhost = 0L))
content <- content(response, "text")
cat(content)
Scrolling to the bottom of these results will allow you to access the detailed results extracted by Serpdog’s Google Scraper. This includes credit information, featured snippets, organic results, and much more that may appear on the search page.
Pros and cons of Using R
Every language has some pros and cons in itself. But, let us discuss some benefits associated with R.
Pros:
- R has a variety of packages, such as rvest and httr, designed for custom web scraping tasks.
- R has excellent community support from developers. If you get stuck in a problem, then various online subreddits and discord servers can assist you.
- R has excellent data manipulation capabilities and can easily parse extracted raw HTML data.
Cons:
- Learning R can be difficult for developers beginning with this language.
- R may not be able to deliver the same kind of performance as compared to other languages like Python and Node JS.
- R cannot be used for scraping dynamically rendered content, as their libraries are specifically designed for scraping static HTML pages.
Conclusion:
In this tutorial, we learned to scrape Google Search Results using R Language. Feel free to message me anything you need clarification on. Follow me on Twitter. Thanks for reading!
