
PHP is one of the most popular server-side scripting languages, first developed by Rasmus Lerdorf in 1994. It is widely used for the development of websites, web applications, and other dynamic web content.
It is a powerful scripting language, and one can leverage this capability to automate web scraping tasks.
Web scraping can be defined as the extraction of data from websites in the form of text, videos, images, and more, which can then be stored in a database or a local file. This technique can be used for various purposes, including SEO, lead generation, market research, and scraping Google search results.
In this tutorial, we’ll be scraping Google Search Results using PHP. We will also discuss why PHP can be a suitable alternative for Google scraping tasks.
By the end of the article, you will have a basic understanding of how to deal with scraping Google Search results, which will also help you leverage this knowledge for other web scraping tasks.
Why PHP for scraping Google?
PHP can be an ideal choice for web scraping tasks because of its wide availability and ease of use. It also provides various libraries to work with HTTP requests and HTML parsing. Additionally, it is easy to learn and is greatly supported by the developer community.
PHP provides one of the most popular HTTP request libraries, cURL, which can be used to extract data from web servers. When used with Simple HTML Dom Parser for HTML parsing, it makes a powerful tool, similar to the combination of Axios and Cheerio in Node JS or Requests and Beautiful Soup in Python.
Overall, PHP is a robust and powerful language, highly efficient for scraping Google and other web scraping applications.
Scraping Google Search Results With PHP
In this tutorial, we’ll be focusing on creating a basic PHP script to scrape the first 10 Google Search Results, including their title, link, and description.
Set-Up:
If you have not already installed PHP, you can watch these videos for the installation.
Requirements:
For scraping Google search results with PHP, we will install a PHP library:
- Simple HTML DOM Parser — It allows you to extract or filter out the required data from the raw HTML.
Process:
So, I assume that you have set up your PHP project. We will start scraping the Google Search Results by making an HTTP request with the help of cURL to extract the raw HTML data. Here is our URL:
https://www.google.com/search?q=php+tutorial&gl=us&hl=en
Let us first import the required libraries:
<?php
require_once 'vendor/autoload.php';
require_once 'simple_html_dom.php';
And now, we will make a function to extract the data.
function getData() {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://www.google.com/search?q=php+tutorial&gl=us&hl=en');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.4951.54 Safari/537.36');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
$html = curl_exec($ch);
Step-by-step explanation:
- First, we initiated a cURL session by using the
curl_init()function. - Next, we set the URL from which we want to extract the data.
- In the following line, we set the header to be passed with the URL as the User Agent, which will help us mimic an organic user.
- After that, we set the return transfer option to ‘true’ so that we can obtain the data in string format.
- Then we put the SSL verifier to false to skip the certificate verification.
- And in last, the session gets executed with the curl_exec($ch) function, and we store the extracted HTML in the $html variable.
Now, we will declare an instance of the Simple HTML DOM Parser to load the extracted HTML into it.
$dom = new simple_html_dom();
$dom->load($html);
Okay 😃, we are done with the scraping part. Now, we will focus on searching for the tags that contain our required elements to parse the HTML.
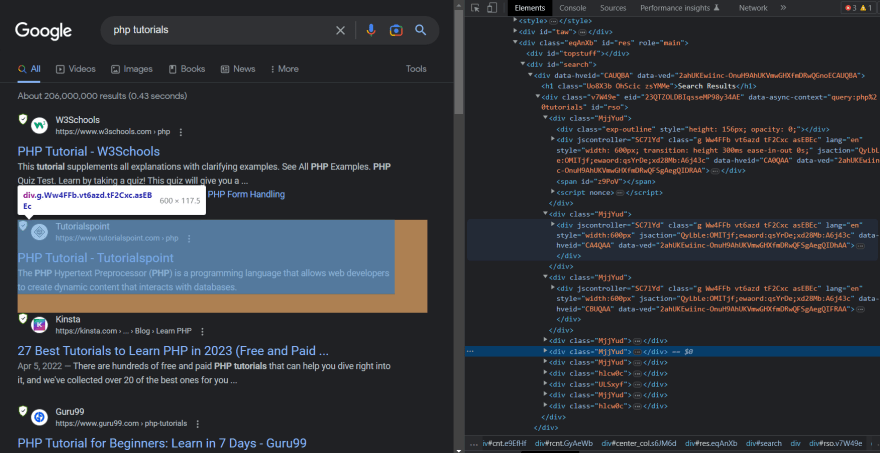
Open the URL in your browser and inspect the HTML code. You will find that every organic result is contained inside the g tag.
So, we will loop over all the divs with the g tag to get the information, it holds inside.
$results = $dom->find("div.g");
This will find all the elements with the class name g.
$c = 0;
foreach ($results as $result) {
// Extract the title and link of the result
$title = $result->find("h3", 0)->plaintext;
$link = $result->find(".yuRUbf a", 0)->href;
$snippet = $result->find(".VwiC3b", 0)->plaintext;
echo "Title: " . $title . "<br>";
echo "Link: " . $link . "<br>";
echo "Snippet: " . $snippet . "<br>";
echo "Position: " . ($c+1) . "<br>";
echo "<br>";
$c++;
}
}
Now, let’s search for the tags of the title, link, and snippet.
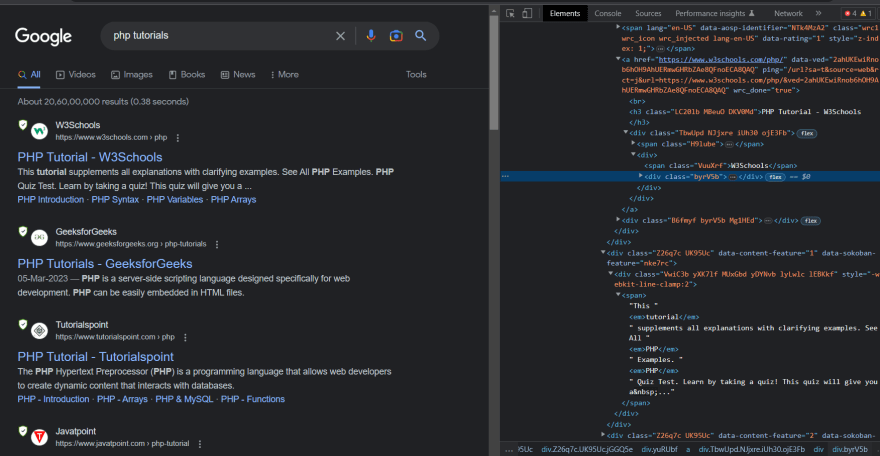
So, from the above image, you can tell that the title has the tag h3, the link has the tag .yuRUbf > a and the snippet has the tag .VwiC3b.
Now, run this code in your terminal. Your results should look like this:
Title: PHP Tutorial - W3Schools
Link: https://www.w3schools.com/php/
Snippet: Learn PHP. PHP is a server scripting language, and a powerful tool for making dynamic and interactive Web pages. PHP is a widely-used, free, and efficient ...
Position: 1
Title: PHP Tutorial - Tutorialspoint
Link: https://www.tutorialspoint.com/php/index.html
Snippet: The PHP Hypertext Preprocessor (PHP) is a programming language that allows web developers to create dynamic content that interacts with databases.
Position: 2
Title: A simple tutorial - Manual - PHP
Link: https://www.php.net/manual/en/tutorial.php
Snippet: Here we would like to show the very basics of PHP in a short, simple tutorial. This text only deals with dynamic web page creation with PHP, though PHP is ...
Position: 3
Great work🎉🎉!!! So, we have successfully created our scraper to scrape Google Search Results in PHP.
However, this solution is not scalable and can result in an IP blockage from Google. Alternatively, you can use various Google Search APIs available in the market, to counter anti-bot mechanisms with their large pool of Data centers and Residential Proxies.
Scraping Google Search Results Using SERP API in PHP
Serpdog provides an easy and streamlined solution to scrape Google Search Results with its robust SERP APIs. Additionally, it also solves the problem of dealing with proxies and CAPTCHAs for a smooth scraping journey. It provides tons of extra data other than organic results in the most affordable pricing in the whole industry.
Getting API Credentials From Serpdog
To extract data from Google SERP, we need an API Key from Serpdog’s user dashboard.
Register on the website and get your API Key, which you can find on the right side of the user dashboard.
Setting Up our code for scraping search results
After getting the API Key, create a new file in your project folder and paste the following PHP code which will collect search results for the query “PHP tutorial” from Google.
<?php
$url = "https://api.serpdog.io/search?api_key=APIKEY&q=php+tutorial&gl=us";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($ch, CURLOPT_HEADER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
$response = curl_exec($ch);
curl_close($ch);
print_r($response);
You can also try to look for results for any other query. Additionally, you can use the below parameters from Serpdog’s Google Search API Documentation to refine the search results.
| num | Type: Number(Integer)
Number of results per page |
| gl | Type: String
Default: |
| hl | Type: String
Default Value: |
| page | Type: Number(Integer) [0,10,20....]Default: 0
(Enter 10 for 2nd-page results, 20 for 3rd, etc .) The page number to get targeted search results. |
| lr | Type: String
Limit the search to one or multiple languages. It is used as |
| uule | Type: String
Use this as The |
| nfpr | Type: BooleanDefault: 0
It excludes the result from an auto-corrected query that is spelled wrong. It can be set to |
| tbs | Type: String
to be searched – An advanced parameter to filter search results. |
| safe | Type: String [active/off]Default: off
To filter the adult content set |
| domain | Type: StringDefault: "google.com"
To obtain local results from a specific country, for example, for India, it will be “google.co.in,” and for the UK, it will be “google.co.uk.” |
Compile and execute the program in your respective code editor.
{
"meta": {
"q": "php tutorial",
"domain": "google.com",
"api_key": "APIKEY"
},
"user_credits_info": {
"quota": 160000,
"requests": 82162,
"requests_left": 77838
},
"search_information": {
"total_results": "About 1,140,000,000 results (0.33 seconds)",
"query_displayed": "php tutorial"
},
"menu_items": [
{
"title": "Videos",
"link": "https://www.google.com/search?sca_esv=1ebb0e033accb772&sca_upv=1&gl=us&hl=en&q=php+tutorial&tbm=vid&source=lnms&prmd=visnbmt&sa=X&ved=2ahUKEwj6gIbowZqGAxWpqJUCHZ-JBgYQ0pQJegQIFRAB",
"position": 1
},
{
"title": "Shopping",
"link": "https://www.google.com/search?sca_esv=1ebb0e033accb772&sca_upv=1&gl=us&hl=en&q=php+tutorial&tbm=shop&source=lnms&prmd=visnbmt&ved=1t:200715&ictx=111",
"position": 2
}
],
I am not able to show the complete response here. However, if you take a look at the response, it has provided you with every detail from the Google Search Page, including organic search results, menu items, related searches, and People Also Ask questions.
Conclusion:
PHP may be an old language, but if utilized effectively, it can be used to create highly efficient web scrapers. In this tutorial, we learned how to get data from Google by creating our own basic scraper with PHP. At the end, we also explored how Serpdog’s API can be used to enhance this process. Feel free to message me anything you need clarification on. Follow me on Twitter. Thanks for reading!