

Booking.com is the largest hotel reservation site in the world, with over 27 million reported listings in 130,000 destinations across 227 countries worldwide. Its vast mine of publicly available data on hotels and resorts makes Booking.com a valuable resource for data miners and the respective OTAs to observe their competitors’ pricing strategies.
In this tutorial, we will learn to scrape Hotel Search Results from Booking.com using Python and BeautifulSoup.
First, we will familiarize ourselves with the HTML structure of the webpage we want to scrape. From there, we will extract important information such as the hotel name, pricing, links, and other relevant information. To wrap up this tutorial, we will explore an efficient solution for scraping hotel data from Booking.com and discuss the benefits of scraping data from hotel reservation websites or OTAs.
By the end of this tutorial, you will be able to scrape pricing and other information from Booking.com. And you can also use this knowledge in creating a Hotel Scraper API in the future to compare the pricing of different vendors on multiple platforms.
Why Python for scraping Booking.com?
Python is a high-performance multipurpose language used greatly in web scraping tasks, usually backed by libraries designed specifically for scraping.
Python also offers various features like excellent adaptability and scalability, enabling it to handle huge amounts of data. Overall it is the most preferred language for web scraping with a large community of active support, which you can utilize to get solutions for any problem.
Read More: Web Scraping With Python
Let’s Start Scraping Booking.com
Before starting our project, let us discuss some requirements, including installing libraries to help us extract Hotel data from Booking.com.
Requirements
I assume that you have already installed Python on your computer. Next, we need to install two libraries which we will use to scrape the data later on.
- Requests — Using this library, we will establish an HTTP connection with Booking.com.
- BeautifulSoup — Using this library, we will parse the extracted HTML data to gather the required information.
Setup
Next, we will make a new directory inside which we will create our Python file and install the libraries mentioned above.
mkdir booking_scraper
pip install requests
pip install beautifulsoup4
It is a good practice to decide in advance which data you need to extract from the webpage.
From the Booking.com search page, we will extract the following data points:
- Name
- Link
- Location
- Rating
- Review count
- Price
- Thumbnail
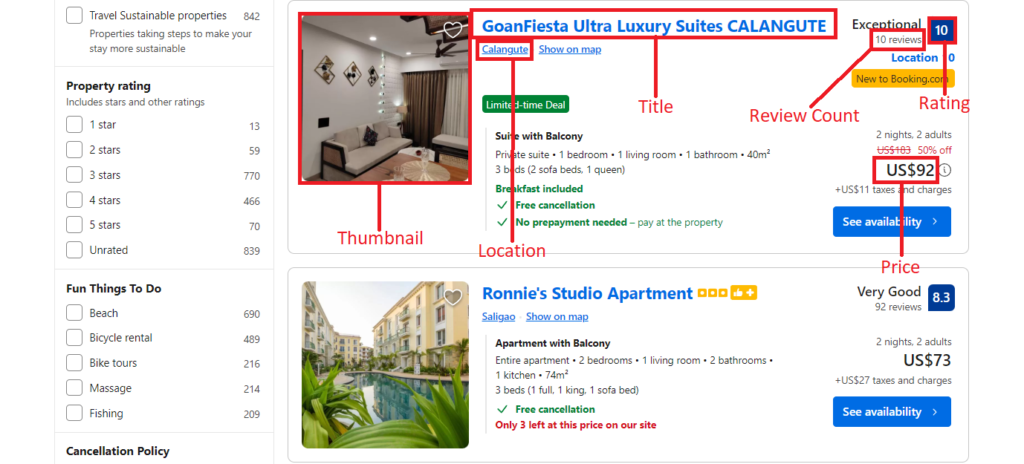
After that, we will select a Hotel Link and also extract data about it.
We will use BeautifulSoup find() and find_all() methods depending on the DOM structure to target DOM elements and extract their data. Furthermore, we will take developer tools’ help to find the CSS path for locating the DOM elements.
Process
Scraping Booking.com Search Page
As we have completed the setup, it’s time to make an HTTP GET request to the target URL, which will be the first and basic part of our code.
import requests
from bs4 import BeautifulSoup
url = "https://www.booking.com/searchresults.html?ss=Goa%2C+India&lang=en-us&dest_id=4127&dest_type=region&checkin=2024-08-28&checkout=2024-08-30&group_adults=2&no_rooms=1&group_children=0p_adults=2&group_children=0&no_rooms=1&selected_currency=USD"
headers={"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5042.108 Safari/537.36"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
print(response.status_code)
hotel_results = []
First, we imported the two libraries we installed. Then, we initialized the URL to the target page and the header to User Agent, which will help our bot to mimic an organic user.
Lastly, we made a GET request to the target URL using the Requests library and created a BeautifulSoup instance to traverse through the HTML and extract information from it.
This completes the first part of the code. Now, we will find the CSS selectors from the HTML to get access to the data.
Extracting the Hotel Name and Link
Let us now start by extracting the title and link of the hotels from the HTML. Point your mouse over the title and right-click it, which will open a menu. Select Inspect from the menu, which will open the Developer Tools.
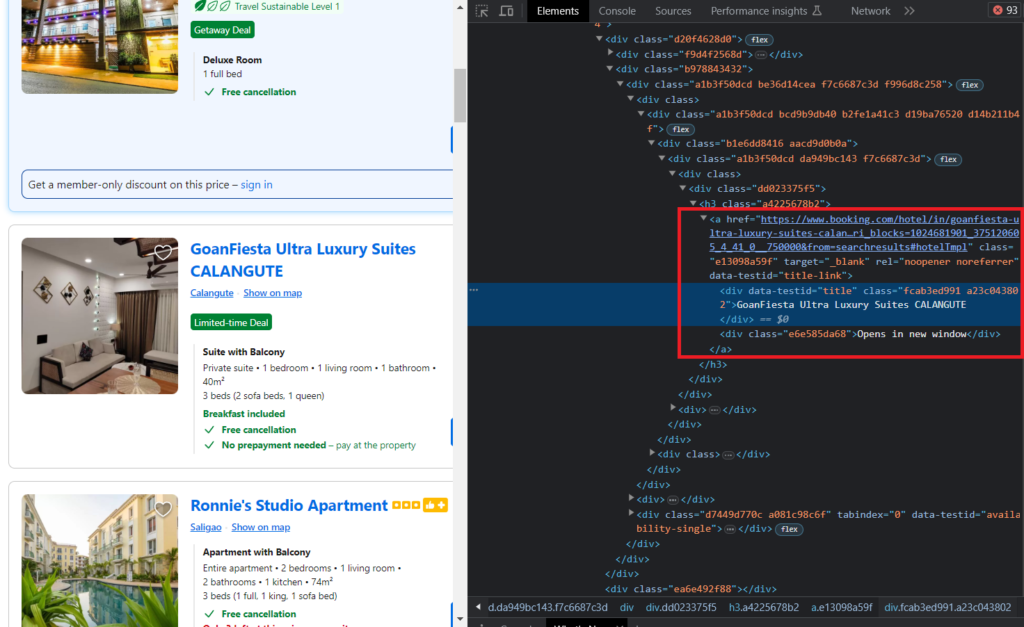
In the above image, you can see the name is located under the anchor tag. The anchor tag consists of the Hotel link and can be identified in the DOM structure using its attribute data-testid=title-link. The div tag under the anchor link also has an attribute data-testid=title that can be used to extract the names of the Hotels. But, we will not just directly scrape them. For simplicity, we will loop through every property card in the list and extract each stated entity step by step.
This is what I meant by property card👇🏻.
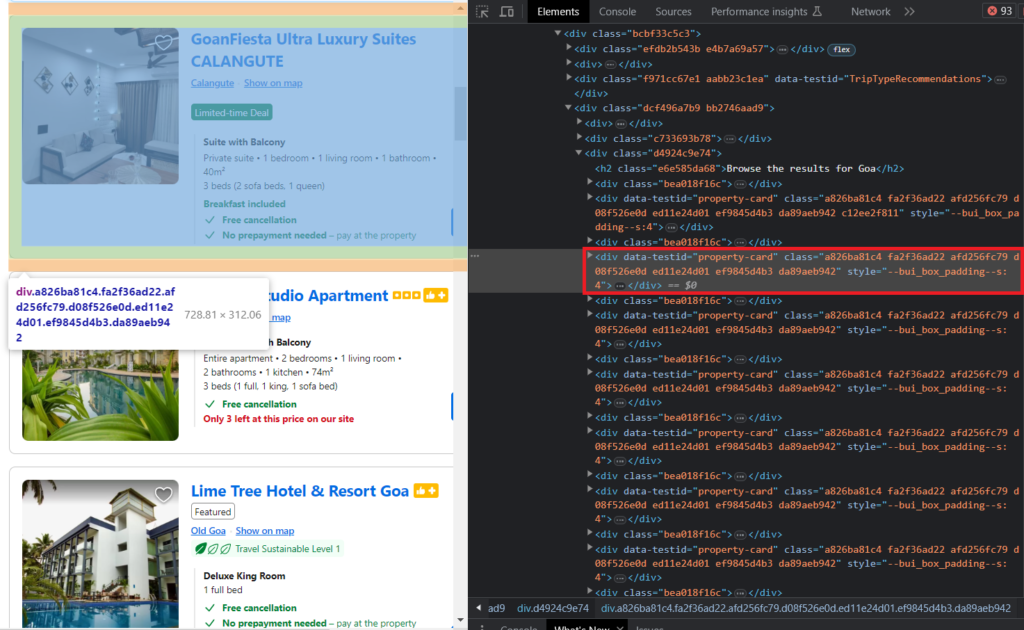
We will use the find_all() of BS4 to target all the property cards.
for el in soup.find_all("div", {"data-testid": "property-card"}):
Next, we will extract the name and link of the respective properties.
hotel_results.append({
"name": el.find("div", {"data-testid": "title"}).text.strip(),
"link": el.find("a", {"data-testid": "title-link"})["href"]
})
Extracting the Hotel Location and Pricing
Similarly, we can extract the Hotel Location and the pricing. After inspecting the location, you will find that it also has a data-testid attribute equal to address.
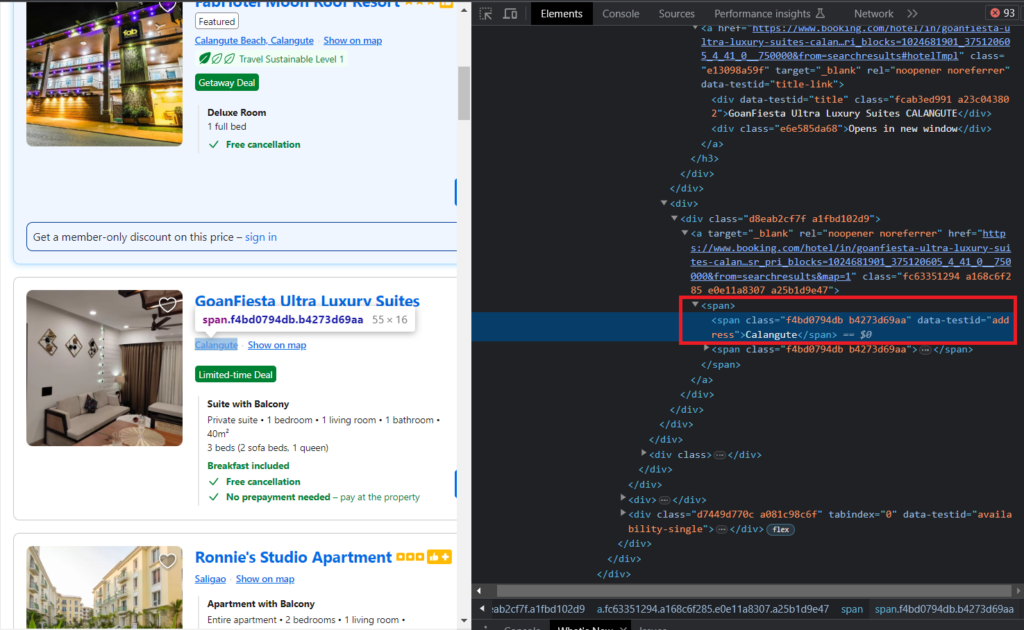
Add the following code to extract the location.
"location": el.find("span", {"data-testid": "address"}).text.strip(),
Next, with the same process, we will extract the pricing.
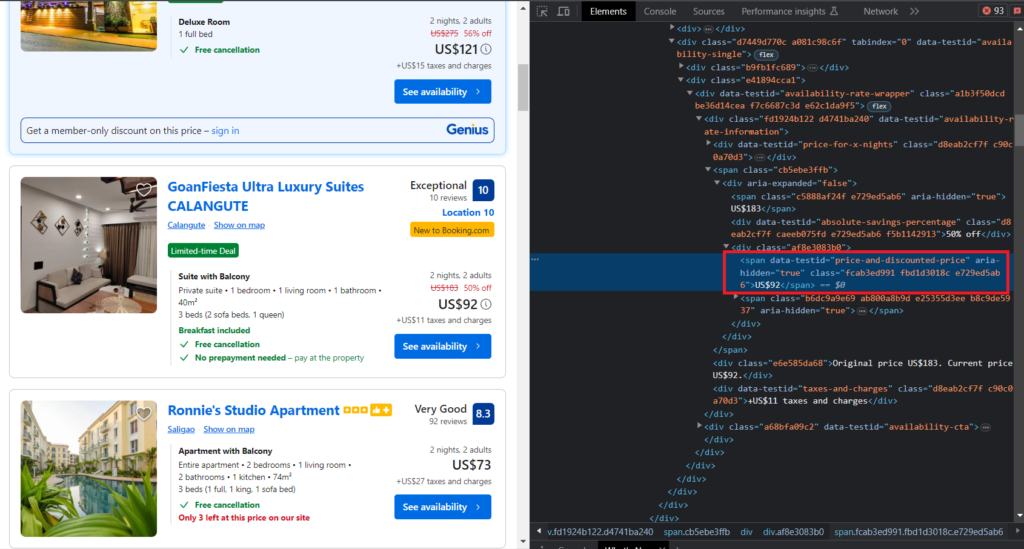
We will be selecting the price after the discount with the attribute data-testid=price-and-discounted-price. If you want to scrape other information like pricing before discount and after taxes, you can add that into your code by following the same process.
Next, add the following code to extract the pricing.
"pricing": el.find("span", {"data-testid": "price-and-discounted-price"}).text.strip(),
Extracting the Hotel Review Count and Rating
The Hotel Review information is encapsulated in the div tag with the attribute data-testid=review-score.
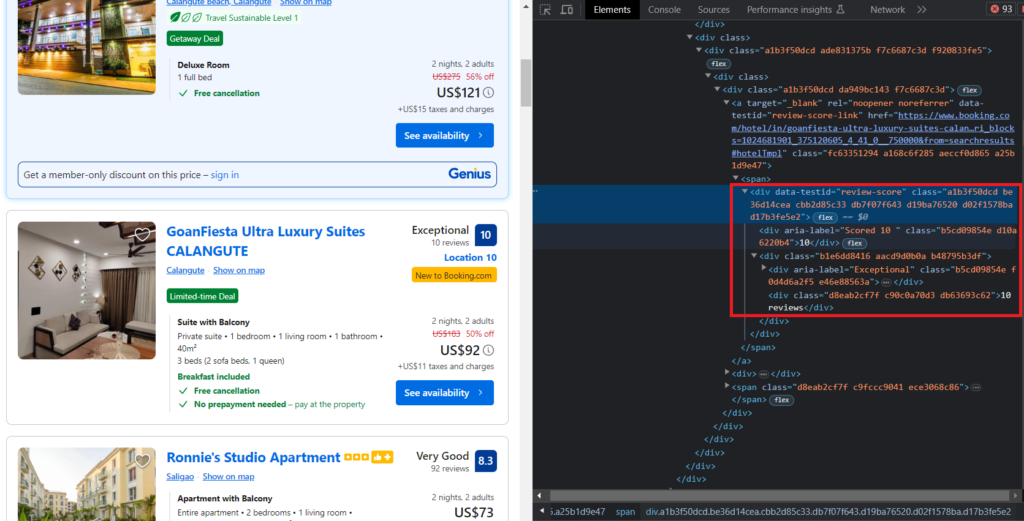
The following code will return you the review information.
"rating": el.find("div", {"data-testid": "review-score"}).text.strip().split(" ")[0],
"review_count": el.find("div", {"data-testid": "review-score"}).text.strip().split(" ")[1],
We are extracting the rating and review count using the split() function. This helps us to get the results separately in the desired format. You can also pull them individually by specifically targeting the div in which they are located.
Extracting the Hotel thumbnail
Finally, we will extract the thumbnail of the Hotel. The thumbnail is easy to find and can be located inside the img tag with attribute data-testid=image.
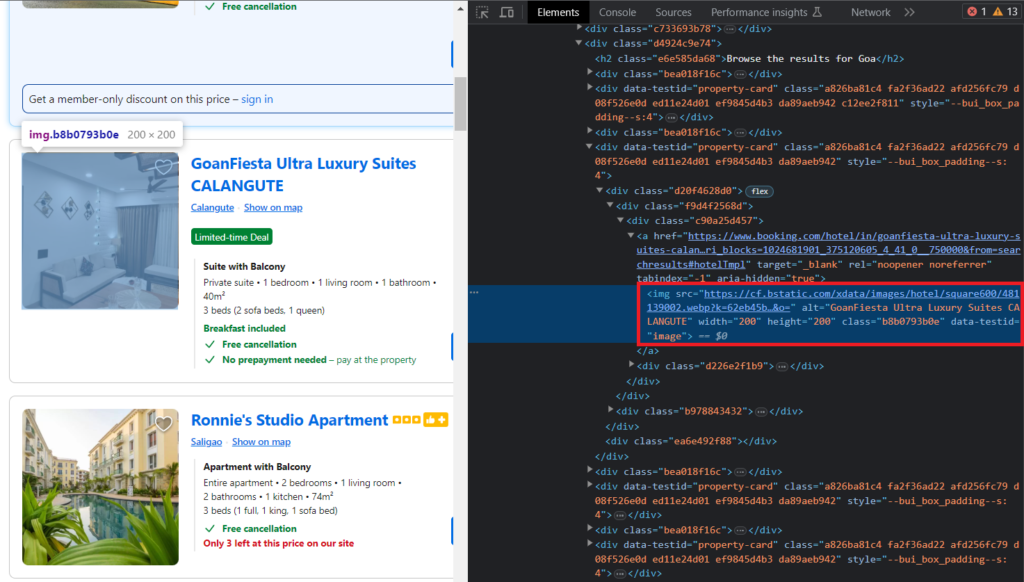
The following code will return you the image source.
"thumbnail": el.find("img", {"data-testid": "image"})['src'],
We have successfully extracted all the desired information from the search results page on Booking.com.
Complete Code
Now, you can also scrape an extra set of information like recommended units consisting of services provided by the Hotel, availability, and the ribbon information that are additional services given on the Hotel thumbnail. You can also change the URL to match the data you want.
You now have the code for scraping names, links, pricing, and reviews of the respective properties. Our scraper should look like this:
import requests
from bs4 import BeautifulSoup
url = "https://www.booking.com/searchresults.html?ss=Goa%2C+India&lang=en-us&dest_id=4127&dest_type=region&checkin=2024-08-28&checkout=2024-08-30&group_adults=2&no_rooms=1&group_children=0p_adults=2&group_children=0&no_rooms=1&selected_currency=USD"
headers={"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5042.108 Safari/537.36"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
print(response.status_code)
hotel_results = []
for el in soup.find_all("div", {"data-testid": "property-card"}):
hotel_results.append({
"name": el.find("div", {"data-testid": "title"}).text.strip(),
"link": el.find("a", {"data-testid": "title-link"})["href"],
"location": el.find("span", {"data-testid": "address"}).text.strip(),
"pricing": el.find("span", {"data-testid": "price-and-discounted-price"}).text.strip(),
"rating": el.find("div", {"data-testid": "review-score"}).text.strip().split(" ")[0],
"review_count": el.find("div", {"data-testid": "review-score"}).text.strip().split(" ")[1],
"thumbnail": el.find("img", {"data-testid": "image"})['src'],
})
print(hotel_results)
Scraping Booking.com Hotel Page
So, we now have the scraper to scrape the Booking.com search page. Moving to the next step, we will target the Hotel name, address, features, description, etc.
We will use the same scraping technique to create an HTTP connection by passing User Agent as the header.
import requests
from bs4 import BeautifulSoup
url = "https://www.booking.com/hotel/in/beach-house-sea-lawns-goa-sernabatim.html?aid=304142&all_sr_blocks=1008190103_397266689_2_42_0;checkin=2024-08-28;checkout=2024-08-30;dest_id=4127;dest_type=region;dist=0;group_adults=2;group_children=0;hapos=1;highlighted_blocks=1008190103_397266689_2_42_0;hpos=1;matching_block_id=1008190103_397266689_2_42_0;no_rooms=1;req_adults=2;req_children=0;room1=A%2CA;sb_price_type=total;sr_order=popularity;sr_pri_blocks=1008190103_397266689_2_42_0__757440;srepoch=1721310561;srpvid=2bf15ff225730290;type=total;ucfs=1&"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5042.108 Safari/537.36"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
print(response.status_code)
hotel_data = {}
hotel_data['name'] = soup.select_one(".hp__hotel-title").text.strip()
hotel_data['description'] = soup.select_one(".hp-description").text.strip()
hotel_data['address'] = soup.select_one(".hp_address_subtitle").text.strip()
facilities = [el.text.strip() for el in soup.select("#hp_facilities_box ul li")]
hotel_data['facilities'] = facilities
print(hotel_data)
This scraper covers the basic data needed from a Booking.com hotel page. You can target more data points using the same parsing technique. However, for this tutorial, we will focus only on the data points mentioned above.
Benefits of Scraping Booking.com
Booking.com has grown to a market capitalization of 111 Billion $ since its launching in 1997. Its gigantic size offers a variety of benefits to data miners:
- Access to a wide range of data — Scraping Booking.com allows you to access a wide range of data on Hotels, customer reviews, location, availability, and much more which can be used for collecting market insights and other relevant information.
- Price Monitoring — You can scrape Booking.com to compare the pricing of hotels on different platforms and select the most affordable option.
- Customer Reviews — Scraping Hotel Reviews from Booking.com allows users to identify the best restaurant from available options. Businesses can do a sentimental analysis based on customer reviews and determine the areas of improvement.
Frequently Asked Questions
How can I scrape Booking.com without getting blocked?
You can scrape Booking.com without getting blocked by using Serpdog’s Web Scraping API, which rotates millions of proxies at its backend, allowing its users to fetch data smoothly and efficiently.
Conclusion
Hotel Data Scraping will grow as the size and market cap of OTAs and other competitors increase with the rise in the hospitality industry. This can be a great opportunity for developers who want to earn money by creating a project that fetches real-time Hotel data from different platforms like Expedia, MakeMyTrip, and more for price comparison and other relevant purposes.
I hope you enjoyed this tutorial. If I missed anything or if you have any questions, please feel free to reach out.
Please do share this blog on Social Media and other platforms. Follow me on Twitter. Thanks for reading!
Additional Resources
Want to learn more about web scraping?
No worries! We have prepared a complete list of tutorials so you can get comfortable while creating your web scraping projects.
