
You might have come across our tutorials on Web Scraping With Node JS, Python, and Java. If you‘re a PHP developer, you might have also encountered our blog to scrape Google Search Results using PHP. But, we never made a dedicated tutorial on using PHP for web scraping.
Web Scraping is the process of extracting a specific set of information from websites. Its popularity has been growing consistently because every company needs data for accurate market insights to grow in the competitive market.
PHP is a powerful scripting language and can be a great choice for rapid and effective web scraping. In this tutorial, we will be learning Web Scraping With PHP and exploring various libraries and frameworks to scrape data from the web in multiple ways😇!
PHP is a popular backend scripting language developed by Rasmus Lerdorf in 1994. It can be used for creating web applications and dynamic content for websites. PHP offers various libraries for web scraping made by its developer community. In this tutorial, we will use Guzzle, Goutte, Simple HTML DOM Parser, and the headless browser Symfony Panther.
Before We Begin, Let Us Discuss Some Requirements Associated With This Project.
Requirements
Please watch these videos if PHP is not installed on your device.
To move forward with this tutorial, it is essential to set up a Composer for installing the libraries in this project.
Now, in your respective code editor, run the following command to create a new folder for your project.
mkdir php_scraping
cd php_scraping
Then, run the following commands to initialize the composer.json file.
composer init --require="php >= 8.2" --no-interaction
composer update
This completes our setup for this tutorial. Let’s start scraping!
Exploring PHP Web Scraping with Guzzle, XML, and XPath
Guzzle is the most used HTTP client for PHP, which allows you to send HTTP requests on target websites. Guzzle offers a variety of features, such as managing request and response bodies, handling authentication, and much more. XML is a markup language similar to HTML used for encoding documents and representing structured data.
XPath provides a flexible way of selecting and addressing XML nodes.
Let us install the Guzzle library with the following code to kickstart our project.
composer require guzzlehttp/guzzle
Well then, if your library is installed, please create a new file in your project folder so we can start working with Guzzle.
For this section of the tutorial, we will target https://scrapeme.live/shop/. This website is specifically designed for practicing web scraping.
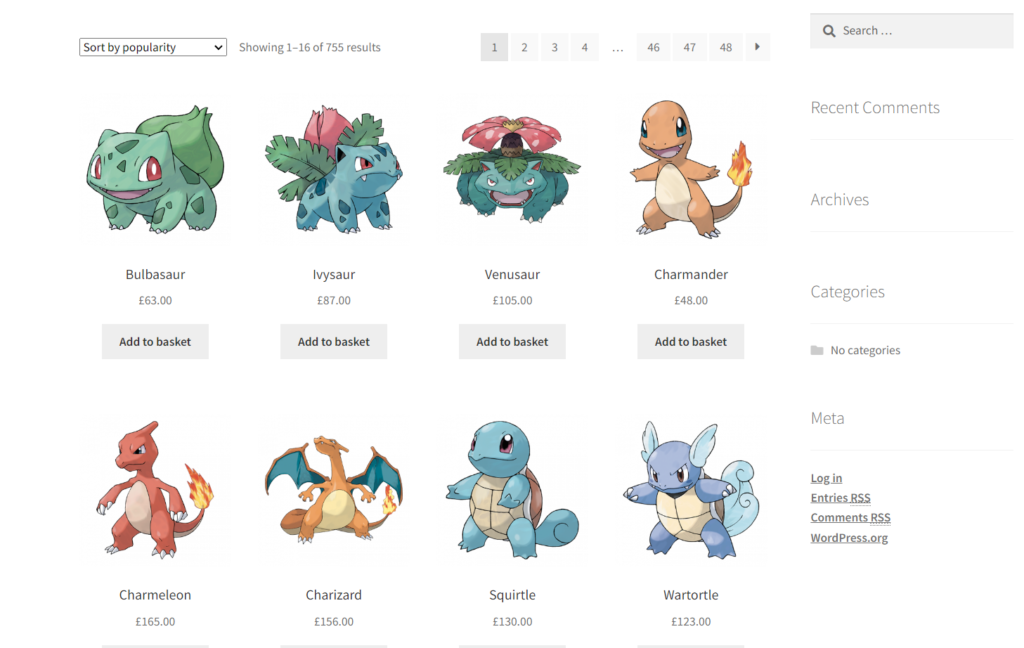
We will extract all product names on the given page. Our next step would be to analyze the structure of the HTML. To step ahead, you should now right-click on the website screen. This will open a menu from which you have to select the Inspect button.
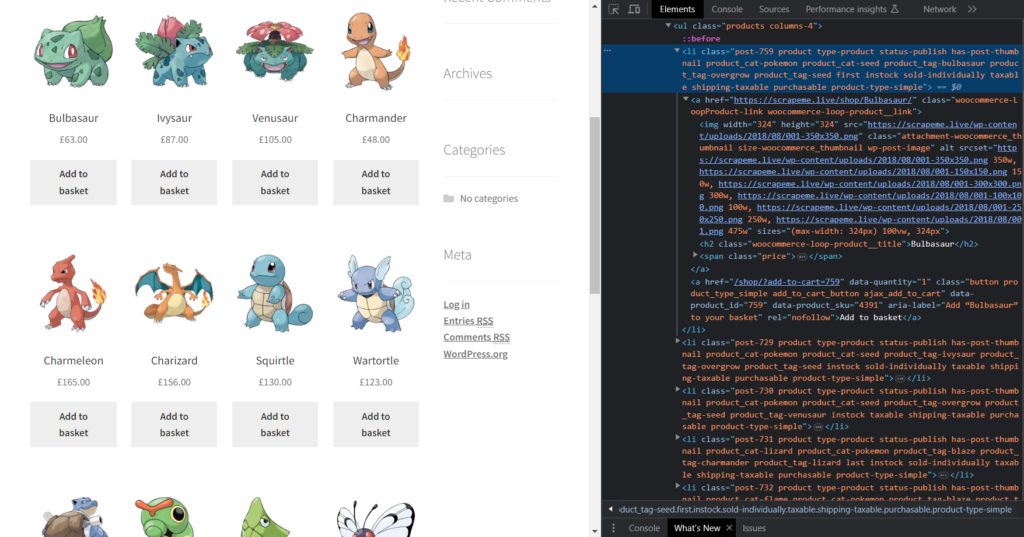
As you can see in the above figure, all of the products are inside the <ul class = products columns-4>.
Then, we have the list of elements with the class product consisting of all the product details, like the title in the <h2> tag and the price in the <span> tag with the class price.
Copy the following code into your respective file to start scraping the website:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$client = new Client();
$response = $client->get('https://scrapeme.live/shop/', ['verify' => false]);
$html = (string) $response->getBody();
$dom = new DOMDocument();
@$dom->loadHTML($html);
After importing the library, we created an instance of Client. Then using this instance, we made an HTTP GET request on the target URL with verify=false so we do not get the SSL error.
After that, we initialized the HTML variable with the response we received. We then created an instance of DOMDocument class to work with XML and HTML documents. This instance is then initialized with the extracted HTML.
$xpath = new DOMXPath($dom);
$productNodes = $xpath->query('//li[contains(@class, "product")]');
We created an XPath instance to target the elements and get the text content inside the sub-elements. Then, with the help of XPath, we targeted all the elements within the class product.
Next, we will iterate through each product and sequentially display their titles.
foreach ($productNodes as $productNode) {
$productName = $xpath->query('.//h2', $productNode)->item(0)->textContent;
echo "Product Name: $productName\n";}
?>
We used the foreach to loop over every product in the list, and then with the help of XPath, we targeted the <h2> tag to extract the title of the products.
Next, run the following command in your terminal to verify if the code is working.
php your_file_name.php
This should print the following output.

🥳🥳Hurray! We successfully scraped our desired target.
What would be the process if we need the pricing of all Pokemon?
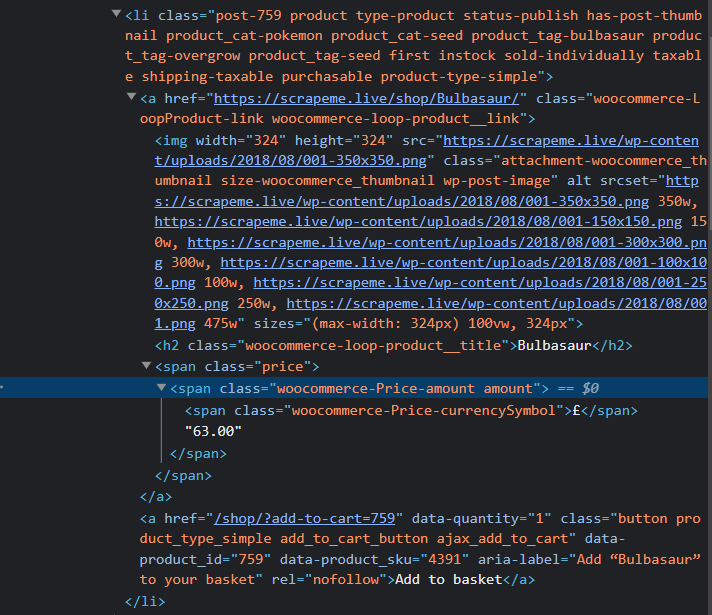
The price is under the element span with the class price. Let us add this also into our code with the title. Copy the following code to extract both the title and the product price.
foreach ($productNodes as $productNode) {
$productName = $xpath->query('.//h2', $productNode)->item(0)->textContent;
$productPrice = $xpath->query('.//span[contains(@class, "price")]', $productNode)->item(0)->textContent;
echo "Product Name: $productName\n";
echo "Product Price: $productPrice\n";
echo "----------------------\n";
}
Run this code in your terminal. The results should look like this:

Here is our complete code:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$client = new Client();
$response = $client->get('https://scrapeme.live/shop/', ['verify' => false]);
$html = (string) $response->getBody();
$dom = new DOMDocument();
@$dom->loadHTML($html);
$xpath = new DOMXPath($dom);
$productNodes = $xpath->query('//li[contains(@class, "product")]');
foreach ($productNodes as $productNode) {
$productName = $xpath->query('.//h2', $productNode)->item(0)->textContent;
$productPrice = $xpath->query('.//span[contains(@class, "price")]', $productNode)->item(0)->textContent;
echo "Product Name: $productName\n";
echo "Product Price: $productPrice\n";
echo "----------------------\n";
}
?>
You can change the code accordingly to extract more data.
Exploring PHP Web Scraping With Goutte
Goutte, an HTTP client library, is explicitly designed for web scraping by the Symfony Framework team. It consists of various Symphony frameworks to make web scraping simpler:
- BrowserKit Component — It is used to mimic the behavior of a web browser.
- DomCrawler Component — It combines the ability of DOMDocument and XPath.
- Symfony HTTP Client — Another part of the Symphony framework used to make HTTP requests.
- CssSelector Component — It converts the CSS selectors to XPath queries.
Run the following command in your terminal to install this library.
composer require fabpot/goutte
Next, create a second file named goutteScraper.php in your project folder to work with Goutte.
In this section, we will discuss two ways of extracting data from HTML using Goutte. We will use the same website that was used in the previous section and extract the titles and pricing of the products as shown on the website.
The first method will involve scraping data using XPath queries with Goutte.
<?php
require 'vendor/autoload.php';
use Goutte\Client;
$client = new Client();
$crawler = $client->request('GET', 'https://scrapeme.live/shop/');
$titles = $crawler->evaluate('//li[contains(@class, "product")]//h2');
$prices = $crawler->evaluate('//li[contains(@class, "product")]//span[contains(@class, "price")]');
$pricingArray = [];
foreach ($prices as $price) {
$pricingArray[] = $price->textContent;
}
foreach ($titles as $key => $title) {
echo "Product Name: $title->textContent\n";
echo "Product Pricing: $pricingArray[$key]\n";
echo "----------------------\n";
}
?>
Run this code in your terminal. Your output should look like this:
Product Name: Bulbasaur
Product Pricing: £63.00
----------------------
Product Name: Ivysaur
Product Pricing: £87.00
----------------------
Product Name: Venusaur
Product Pricing: £105.00
----------------------
Product Name: Charmander
Product Pricing: £48.00
----------------------
Product Name: Charmeleon
Product Pricing: £165.00
This completes our first method of scraping data using Goutte.
Now, instead of using the XPath, we will employ a simple method offered by Goutte. The CSSSelector Component is easier to use than the XPath evaluation. Let’s give it a try!
You can create another file goutte_css_selector_scraper.php for trying this method.
Here is the code:
<?php
require 'vendor/autoload.php';
use Goutte\Client;
$client = new Client();
$crawler = $client->request('GET', 'https://scrapeme.live/shop/');
$titles = $crawler->filter('li.product h2');
$prices = $crawler->filter('li.product span.price');
$pricingArray = [];
foreach ($prices as $price) {
$pricingArray[] = $price->textContent;
}
foreach ($titles as $key => $title) {
echo "Product Name: " . $title->textContent . "\n";
echo "Product Pricing: " . $pricingArray[$key] . "\n";
echo "----------------------\n";
}
?>
The above code looks clearer and more readable than the previous one. Thanks to the Symfony team for adding this component to Goutte.
Run the following command to execute this code:
php goutte_css_selector_scraper.php
As expected, you will see the same output.
Great progress so far! Now, let’s take a look at the process for scraping information simultaneously with pagination.
Pagination is the tricky part. If the whole content is on one page, then you may not face this problem. To solve this problem, we will use a for loop till the end of the page. With each iteration, we will extract the data present on the web page till we reach the end of the web page.
Install this library before you try this code.
composer require symfony/dom-crawler
Copy the following code to implement this functionality.
<?php
require 'vendor/autoload.php';
use Goutte\Client;
$client = new Client();
$fetchData = function ($url) use ($client) {
$response = $client->request('GET', $url);
return $response->getBody()->getContents();
};
$scrapeDataFromPage = function ($html) {
$crawler = new Symfony\Component\DomCrawler\Crawler($html);
$crawler->filter('li.product')->each(function ($node) {
$productName = $node->filter('h2')->text();
$productPrice = $node->filter('span.price')->text();
echo 'Product Name: ' . $productName . PHP_EOL;
echo 'Product Pricing: ' . $productPrice . PHP_EOL;
echo '----------------------' . PHP_EOL;
});
};
$getData = function () use ($fetchData, $scrapeDataFromPage) {
$url = 'https://scrapeme.live/shop/';
$html = $fetchData($url);
$scrapeDataFromPage($html);
$crawler = $client->request('GET', $url);
$totalPages = (int)$crawler->filter('li:nth-child(8) .page-numbers')->first()->text();
for ($i = 2; $i <= $totalPages; $i++) {
$url = "https://scrapeme.live/shop/page/{$i}";
$html = $fetchData($url);
$scrapeDataFromPage($html);
}
};
$getData();
Now, run this code in your terminal. You will get data on all the products present on that webpage.
So, now you also know how to implement pagination. Let us move to the third library of the tutorial.
Exploring PHP Web Scraping with Simple HTML DOM Parser
Simple HTML DOM Parser is another excellent PHP web-scraping library that allows you to parse and manipulate HTML conveniently. It is one of the most widely used libraries among PHP developers for web scraping tasks because of its simplicity and ease of use.
Let us install this library by running the following command.
composer require simplehtmldyour om/simplehtmldom
Now, create a new file named simple_html_dom_scraper.php in your project folder to work with this library.
Our target will be the same website. Additionally, we have already discussed the HTML structure, so we will not go into detail about it here. Copy the following code to your file.
<?php
require 'simple_html_dom.php'; // Include the Simple HTML DOM Parser library
$url = 'https://scrapeme.live/shop/';
// Get the HTML content from the URL
$html = file_get_html($url);
$titles = $html->find('li.product h2');
$prices = $html->find('li.product span.price');
$pricingArray = [];
foreach ($prices as $price) {
$pricingArray[] = html_entity_decode($price->plaintext);
}
foreach ($titles as $key => $title) {
echo "Product Name: " . $title->plaintext . "\n";
echo "Product Pricing: " . $pricingArray[$key] . "\n";
echo "----------------------\n";
}
// Clean up the Simple HTML DOM object
$html->clear();
unset($html);
?>
The output will be the same as before.
Exploring PHP Web Scraping With a Headless Browser
Scraping websites that do not use dynamic content on their web page is a lot easier. However, modern websites like Instagram and Twitter use JavaScript frameworks at their backend to load the HTML content dynamically. In other words, they use AJAX to load content dynamically. A simple HTTP request is not suitable for getting access to this dynamic content. This problem is solved by using “Headless Browsers.”
Headless Browsers are browsers operating without any user interface. They can be controlled programmatically and automated through code. They are commonly used for performing web scraping tasks to scrape websites that use JavaScript at the backend to load the content dynamically.
Symfony Panther, a PHP web scraping library working on the same APIs as Goutte, can be used for Headless Browser purposes. This library provides the same methods as in Goutte and can be used as an alternative to Goutte. Let us discuss some features associated with Symfony:
- It can be used to take screenshots and PDFs of web pages.
- Supports execution of JavaScript.
- It can be used for form submissions.
- Supports navigation through web pages.
You can install this library by the following command.
composer require symfony/panther
Next, create a new file symphony_scraper.php in your project folder with the following code.
Finally, we will install the web drivers for Chrome and Firefox using the composer. Run the following command in your terminal:
composer require — dev dbrekelmans/bdi
vendor/bin/bdi detect drivers
Here is the code for getting a PDF of the target web page.
<?php
require 'vendor/autoload.php';
$httpClient = \Symfony\Component\Panther\Client::createChromeClient();
// for a Firefox client use the line below instead
//$httpClient = \Symfony\Component\Panther\Client::createFirefoxClient();
$response = $httpClient->get('https://scrapeme.live/shop/');
// save the page as a PDF in the current directory
$response->savePDF('scrapeme.pdf');
?>
Next, run this code in your terminal, and it will create a PDF of the target website in your project folder.
You can even modify the code and perform button-clicking and form submission tasks to get an idea of working with Headless Browsers.
Conclusion
In this tutorial, we learned about various open-source libraries in PHP and multiple ways to scrape data from the web. The knowledge you gained in this tutorial can be implemented to create scalable web scrapers to scrape massive amounts of data from the web.
If you think we can complete your web scraping tasks and help you collect data, please don’t hesitate to contact us.
I hope this tutorial gave you a complete overview of web scraping with PHP. Please do not hesitate to message me if I missed something. Follow me on Twitter. Thanks for reading!
Additional Resources
I have prepared a complete list of blogs to learn web scraping that can give you an idea and help you in your web scraping journey.