
Zillow is one of the most popular real estate websites in the world. Having more than 135 million registered properties makes it a highly data-rich website. Even the term Zillow is used more often on Google than the keyword “real estate”.
With the increasing interest in obtaining valuable information about the real estate market, acquiring data from Zillow has become a necessary tool to help analyze data and provide clients with the perfect property according to their budget and other requirements.
Python, the most popular choice for web scraping, can be a helpful tool for scraping data-rich websites like Zillow.com, Realtor.com, and more.
In this tutorial, we will create a web scraping tool to gather data from Zillow.com using Python and its libraries.
Why Scrape Zillow?
There are a variety of reasons why someone might want to pull data from Zillow:
Market Research — It allows you to analyze market sentiments based on trends such as property pricing, housing trends, location trends, etc.
Property Analysis — Homeowners can make an informed analysis of the valuation of their house by scraping property prices from Zillow in their neighborhood.
Price Tracking — It can assist real estate agents and investors in keeping track of property prices available in a particular area and adjusting their strategies based on expected future trends.
Why Python for scraping Zillow data?
As we know, Python is one of the most popular choices for web scraping, which is only possible because of its powerful libraries like Requests, Beautiful Soup, Selenium, etc. These libraries simplify the process of extracting data from websites like Zillow.com and also accelerate it to a great extent.
Also, Python has great community support and can provide answers to any question, especially if you are new to web scraping. There are various communities related to Python programming open to the public on Reddit and Discord, which can help you immediately if you are facing any problems:
Let’s start scraping Zillow using Python
In this post, we will make a basic Python Script to scrape pricing, address, size of the properties, and much more from this page.
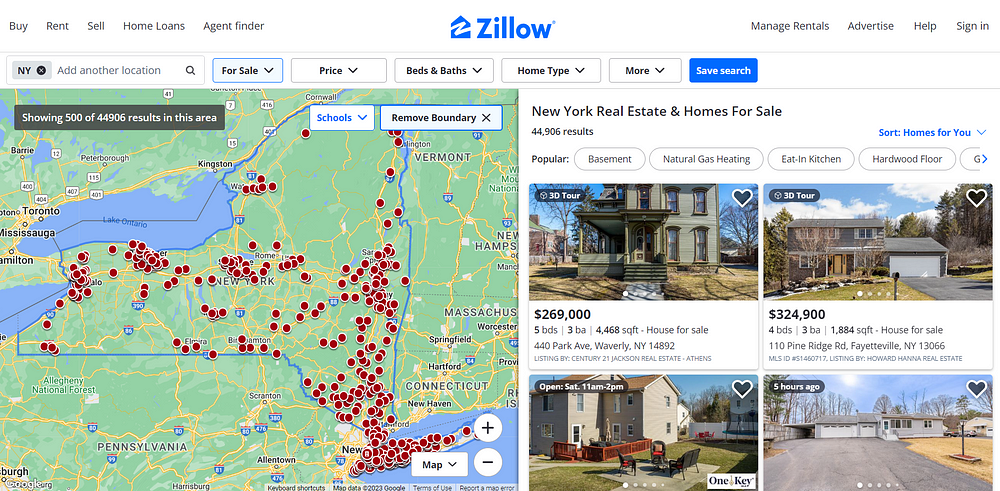
Requirements
To start scraping Zillow, we first need to install some libraries to begin our project:
- Requests — To extract the HTML data from the Zillow website.
- Beautiful Soup — For parsing the extracted HTML data.
Or you can just run the below commands in your project terminal to install these libraries:
pip install requests
pip install beautifulsoup4
Process:
Method 1 — With a Simple HTTP GET request
Before starting the tutorial, I assume you have already set up the project folder on your device. So, now open the project file in your respective code editor and import the libraries we have installed above.
import requests
from bs4 import BeautifulSoup
Let us declare the list in which we will store our extracted data, and also declare the headers variable.
l=list()
obj={}
headers= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
"Accept-Language":"en-US,en;q=0.9",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding":"gzip, deflate, br",
"upgrade-insecure-requests":"1"
}
url = "https://www.zillow.com/homes/for_sale/New-York_rb/"
resp = requests.get(url, headers=headers).text
After declaring the headers, we set the target URL and used it for extracting the HTML data using the request library.
Then, we will search for the required elements from the HTML to get the filtered data.
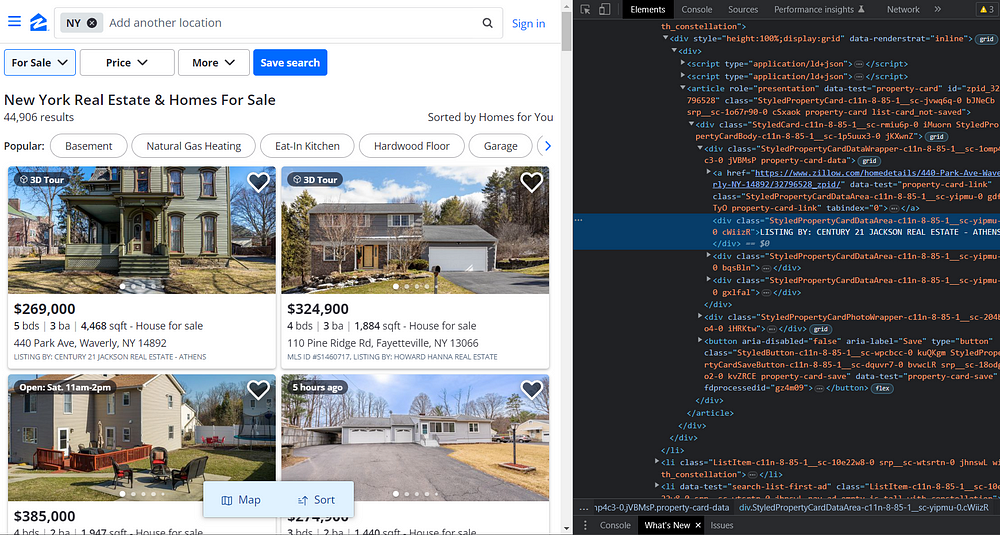
If you inspect the HTML, you will find that the price is under the tag .bqsBln span, address is under the tag address and the size is under the tag .gxlfal.
Similarly, you can also find tags for other elements you like to include in your response.
import requests
from bs4 import BeautifulSoup
l=list()
obj={}
headers= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
"Accept-Language":"en-US,en;q=0.9",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding":"gzip, deflate, br",
"upgrade-insecure-requests":"1"
}
url = "https://www.zillow.com/homes/for_sale/New-York_rb/"
resp = requests.get(url, headers=headers).text
soup = BeautifulSoup(resp,'html.parser')
for el in soup.select(".StyledListCardWrapper-srp-8-100-8__sc-wtsrtn-0"):
try:
obj["pricing"]=el.select_one(".fIxunP").text
except:
obj["pricing"]=None
try:
obj["size"]=el.select_one(".kXauQM").text
except:
obj["size"]=None
try:
obj["address"]=el.select_one("address").text
except:
obj["address"]=None
try:
obj["listing_by"] = el.select_one(".StyledPropertyCardDataArea-c11n-8-100-8__sc-10i1r6-0").text
except:
obj["listing_by"] = None
l.append(obj)
obj={}
print(l)
After getting the response from the HTTP request we used Beautiful Soup to create a DOM structure and ran a loop over the StyledCard-c11n-8–85–1__sc-rmiu6p-0 class to extract the required information.
Here are the results:
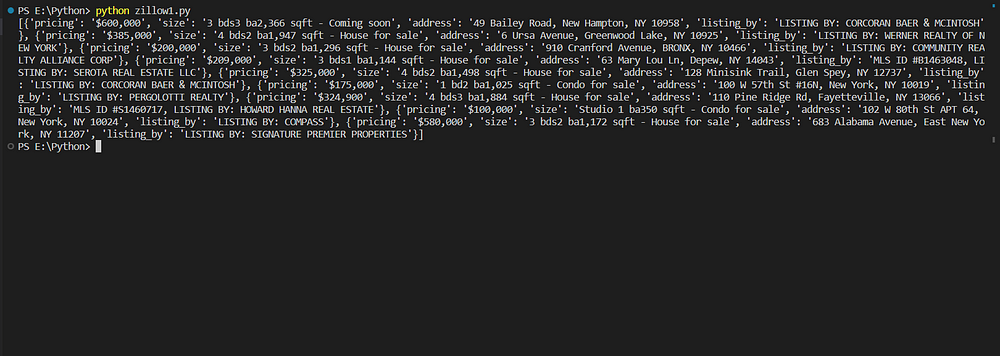
But here’s the catch! We are only able to retrieve nine results, while there are 40 results on the page. The reason for this is that scraping Zillow completely requires Javascript Rendering, which we will cover shortly.
So, if you take a look at the page again, you will find that there are 44,941 listings and 40 listings on each page. Therefore, there are approximately 1123 pages that cover all these listings. However, for informative purposes, we will run a loop on only 10 pages.
import requests
from bs4 import BeautifulSoup
l=list()
obj={}
headers= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
"Accept-Language":"en-US,en;q=0.9",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding":"gzip, deflate, br",
"upgrade-insecure-requests":"1"
}
for i in range(0,10):
resp = requests.get("https://www.zillow.com/homes/for_sale/New-York_rb/{}_p/".format(i), headers=headers).text
soup = BeautifulSoup(resp,'html.parser')
for el in soup.select(".StyledListCardWrapper-srp-8-100-8__sc-wtsrtn-0"):
for el in soup.select(".StyledListCardWrapper-srp-8-100-8__sc-wtsrtn-0"):
try:
obj["pricing"]=el.select_one(".fIxunP").text
except:
obj["pricing"]=None
try:
obj["size"]=el.select_one(".kXauQM").text
except:
obj["size"]=None
try:
obj["address"]=el.select_one("address").text
except:
obj["address"]=None
try:
obj["listing_by"] = el.select_one(".StyledPropertyCardDataArea-c11n-8-100-8__sc-10i1r6-0").text
except:
obj["listing_by"] = None
l.append(obj)
obj={}
print(l)
So, this is how you can scrape data from multiple pages with a simple HTTP request by changing the URL each time the value of the loop variable changes.
Method 2 — With JS rendering
In this section, we will discuss how we can scrape Zillow completely using JS rendering. As Zillow loads its content dynamically, it is required to load its content in the web browser to extract its data.
We will use the Selenium web driver for this operation. Run the below command to install it.
pip install selenium
Now, we need to install a Chrome driver so that we can use Selenium. You can download it from this link. Read the installation guide carefully, you have to install the Driver the same as your Chrome browser version.
Let us now import all the libraries, which we will be using in this section.
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
from bs4 import BeautifulSoup
import time
After that, set the path in your code where your Chrome driver is located.
SERVICE_PATH = "E:\chromedriver.exe"
l=list()
obj={}
headers= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
"Accept-Language":"en-US,en;q=0.9",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding":"gzip, deflate, br",
"upgrade-insecure-requests":"1"
}
url = "https://www.zillow.com/homes/for_sale/New-York_rb/"
My Chrome Driver is located in E drive. Choose the location where your Chrome Driver is located.
Then, we will use the web driver to utilize the Chrome Driver located at the given path and then navigate to the target URL in the Chrome web browser.
service = Service(SERVICE_PATH)
driver = webdriver.Chrome(service=service)
driver.get(url)
Let us now select the HTML tag on the web page so that we can scroll the web page to the bottom afterward.
html = driver.find_element("tag name", 'html')
html.send_keys(Keys.END)
time.sleep(5)
After selecting the HTML tag, we used the send_keys() method which scrolls the page to the bottom. After scrolling, we wait for 5 seconds so that the web page can load completely.
resp = driver.page_source
driver.close()
After fully loading the page, we asked the driver for the HTML content on the web page and then closed it.
Then we will parse the HTML content using Beautiful Soup.
soup=BeautifulSoup(resp,'html.parser')
for el in soup.select(".StyledCard-c11n-8-85-1__sc-rmiu6p-0"):
for el in soup.select(".StyledListCardWrapper-srp-8-100-8__sc-wtsrtn-0"):
try:
obj["pricing"]=el.select_one(".fIxunP").text
except:
obj["pricing"]=None
try:
obj["size"]=el.select_one(".kXauQM").text
except:
obj["size"]=None
try:
obj["address"]=el.select_one("address").text
except:
obj["address"]=None
try:
obj["listing_by"] = el.select_one(".StyledPropertyCardDataArea-c11n-8-100-8__sc-10i1r6-0").text
except:
obj["listing_by"] = None
l.append(obj)
obj={}
print(l)
It is the same code we used in the previous method.
Run this code in your terminal. You will get all the 40 results listed on the web page.
[
{
pricing: '$269,000',
size: '5 bds3 ba4,468 sqft - House for sale',
address: '440 Park Ave, Waverly, NY 14892',
listing_by: 'LISTING BY: CENTURY 21 JACKSON REAL ESTATE - ATHENS'
},
{
pricing: '$324,900',
size: '4 bds3 ba1,884 sqft - House for sale',
address: '110 Pine Ridge Rd, Fayetteville, NY 13066',
listing_by: 'MLS ID #S1460717, LISTING BY: HOWARD HANNA REAL ESTATE'
},
So, this is how you can scrape all the results listed on the web page by using JS rendering.
Is scraping Zillow legal?
Scraping real estate data from Zillow has become increasingly popular in recent years, as it allows investors to track listings over several years and gain a competitive advantage over other players in the market. However, following certain rules and regulations while scraping a website is important to avoid crossing any legal boundaries.
But, if you are scraping the publicly available data for house listings then it is not illegal.
The best way to avoid any violation of legal ethics is to use the official Zillow API, which provides information like house pricing, property details, location details, etc. It is also an authorized way to access the Zillow data.
Scraping Zillow Using Web Scraping API
Zillow is not easy to scrape, and your IP can be blocked by its anti-bot mechanism immediately.
Instead, you can use our scalable and robust solution for scraping Zillow. Our Web Scraping API is equipped with a massive pool of 10 million plus proxies which allows you to extract data from Zillow without any fear of getting blocked.
After using our API:
- You don’t have to parse the complex HTML to filter out the required data, as we have done this part for you on our end.
- You don’t have to manage proxy bans and CAPTCHAs.
- You don’t have to invest much in managing headless browsers to scrape Zillow data.
You can sign up on our website from here.
After registering successfully, you will get an API Key, which you can embed in the code below to scrape Zillow data.
import requests
payload = {'api_key': 'APIKEY', 'url':'YOUR_URL' }
resp = requests.get('https://api.serpdog.io/scrape', params=payload)
print (resp.text)
Conclusion
This tutorial taught us to scrape Zillow Home Listings using Python with multiple methods. We also learned why developers nowadays scrape Zillow and why Python is one of the best options for extracting data from Zillow.
Feel free to message me anything you need clarification on. Follow me on Twitter. Thanks for reading!
Additional Resources
I have prepared some high-quality tutorials that can help kick-start your web scraping journey.