

Google Maps Data is a crucial piece of information for software companies, sentimental analysts, and data miners as it consists of valuable details like user ratings and reviews, phone numbers, addresses, images, and other relevant attributes about a particular location.
Furthermore, Google Maps data serves businesses by allowing them to verify their geographical presence, gather insights into their competitors, and optimize their local SEO efforts.
The limitations imposed by the official Google Maps API have discouraged developers from directly extracting Google Maps data via the official API. Consequently, they migrated towards third-party solutions to meet their requirements. Moreover, the official API has much higher pricing, rendering it an unfeasible solution for many.
Remember, you can also design your scraper, giving you complete control over the results.
This tutorial will teach us to scrape Google Maps with Python using Selenium.
Let’s start scraping
Before starting the tutorial, let’s discuss the requirements necessary to complete this.
User Agents
User-Agent is used to identify the application, operating system, vendor, and version of the requesting user agent, which can save help in making a fake visit to Google by acting as a real user.
You can also rotate User Agents, read more about this in this article: How to fake and rotate User Agents using Python 3.
If you want to further safeguard your IP from being blocked by Google, try these 10 Tips to avoid getting Blocked while Scraping Websites.
Install Libraries
Before we begin, install these libraries so we can move forward and prepare our scraper.
Or you can type the below commands in your project terminal to install the libraries:
pip i selenium
Process
Before proceeding with the tutorial, let us outline the data points we are going to scrape:
- Place Name or Title
- Rating and Reviews
- Address
- Place Description
- Timings
- And other relevant data…
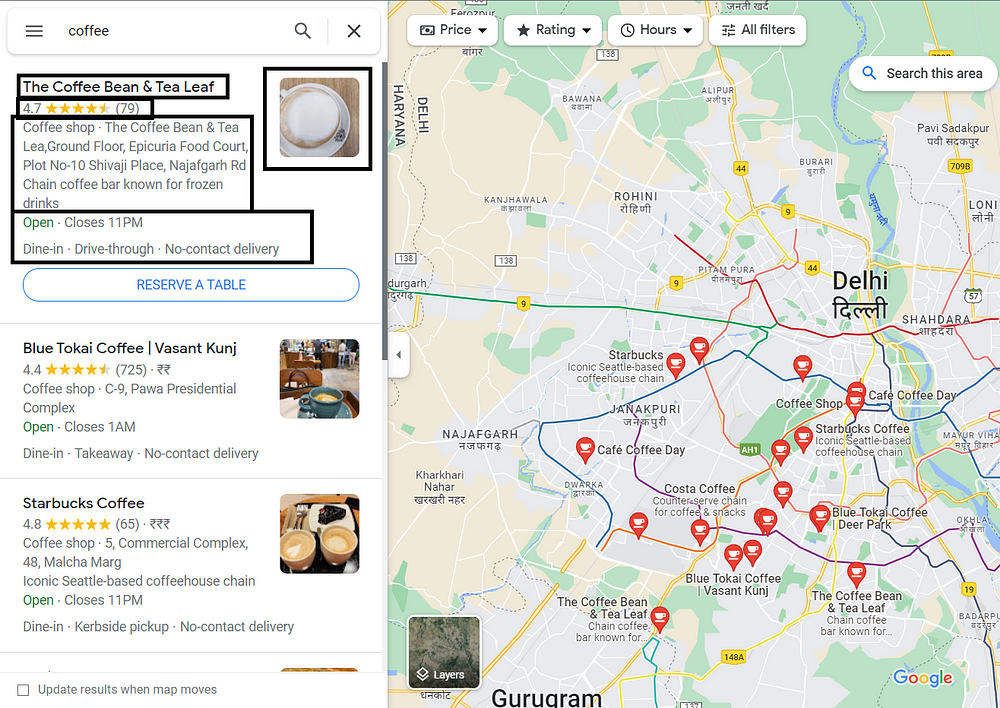
Copy the below target URL to extract the HTML data:
https://www.google.com/maps/search/coffee/@28.6559457,77.1404218,11z
Coffee is our query. After that, we have our latitudes and longitudes. The number before z at the end is nothing but the zooming intensity of Google Maps. You can decrease or increase it as per your choice. Its value ranges from 2.92, in which the map completely zooms out, to 21, in which the map completely zooms in.
Note: Latitudes and longitudes are required to pass in the URL. But the zoom parameter is optional.
First, we will import the required library into the program and initialize our Chrome driver to scrape Google Maps results.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
chrome_options.add_argument("--headless")
service = Service('E:\chromedriver.exe')
driver = webdriver.Chrome(service=service, options=chrome_options)
The webdriver provides an API for controlling the web browser and the Service module will be controlling the Chrome Browser. By module will be used for locating HTML elements and Options allows us to set options on our Chrome browser.
After that, we created an instance of Options and added the argument headless to run the browser in headless mode.
Using Service we specify the path for our ChromeDriver. You have to use your actual path where the ChromeDriver is in your system.
Finally, we initialized the driver with the path and the options that we made earlier.
Now, we will create a main function to launch the browser and navigate to the target URL.
def get_maps_data():
driver.get("https://www.google.com/maps/search/Starbucks/@26.8484046,75.7215344,12z/data=!3m1!4b1")
time.sleep(5)
data = scroll_page(driver, ".m6QErb[aria-label]", 2)
print(data)
driver.quit()
Step-by-step explanation:
driver.get()– This will navigate the page to the specified target URL.time.sleep()– It will cause the page to wait for 5 seconds to do further operations.scrollPage()– At last, we called our infinite scroller with the parameters including the driver, the tag for the scroller, and the number of items we will scroll at a time.
We will use the Infinite Scrolling Method to scrape the Google Maps Results. So, let us start preparing our scroller.
def scroll_page(page, scroll_container, item_target_count):
items = []
previous_height = driver.execute_script(f"return document.querySelector('{scroll_container}').scrollHeight")
while len(items) < item_target_count:
items = extract_items(page)
driver.execute_script(f"document.querySelector('{scroll_container}').scrollTo(0, document.querySelector('{scroll_container}').scrollHeight)")
driver.execute_script(f"return document.querySelector('{scroll_container}').scrollHeight > {previous_height}")
time.sleep(2)
return items
Step-by-step explanation:
previousHeight– Scroll the height of the container.extractItems()– Function to parse the scraped HTML.- In the next step, we just scrolled down the container to a height equal to
previousHeight. - In the last step, we waited for the container to scroll down until its height became larger than the previous height.
Finally, we will discuss the working of our parser.
def extract_items(page):
maps_data = []
items = page.find_elements(By.CSS_SELECTOR, ".Nv2PK")
for el in items:
link = el.find_element(By.CSS_SELECTOR, "a.hfpxzc").get_attribute("href")
data = {
"title": el.find_element(By.CSS_SELECTOR, ".qBF1Pd").text.strip(),
"avg_rating": el.find_element(By.CSS_SELECTOR, ".MW4etd").text.strip(),
"reviews": el.find_element(By.CSS_SELECTOR, ".UY7F9").text.replace("(", "").replace(")", "").strip(),
"address": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(1) > span:last-child").text.replace("·", "").strip(),
"description": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(2)").text.replace("·", "").strip(),
"website": el.find_element(By.CSS_SELECTOR, "a.lcr4fd").get_attribute("href"),
"category": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(1) > span:first-child").text.replace("·", "").strip(),
"timings": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(3) > span:first-child").text.replace("·", "").strip(),
"phone_num": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(3) > span:last-child").text.replace("·", "").strip(),
"extra_services": el.find_element(By.CSS_SELECTOR, ".qty3Ue").text.replace("·", "").replace(" ", " ").strip(),
"latitude": link.split("!8m2!3d")[1].split("!4d")[0],
"longitude": link.split("!4d")[1].split("!16s")[0],
"link": link,
"dataId": link.split("1s")[1].split("!8m")[0],
}
maps_data.append(data)
return maps_data
Step-by-step explanation:
page.find_elements()– It will return all the elements that match the specified CSS selector. In our case, it isNv2PK.get_attribute()-This will return the attribute value of the specified element.text– It returns the text content inside the selected HTML element.split()– Used to split a string into substrings with the help of a specified separator and return them as an array.strip()– Removes the spaces from the starting and end of the string.replace()– Replaces the specified pattern from the whole string.
Complete Code:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
chrome_options.add_argument("--headless") # Run Chrome in headless mode (without GUI)
service = Service('/path/to/chromedriver') # Specify the path to your chromedriver executable
driver = webdriver.Chrome(service=service, options=chrome_options)
def extract_items(page):
maps_data = []
items = page.find_elements(By.CSS_SELECTOR, ".Nv2PK")
for el in items:
link = el.find_element(By.CSS_SELECTOR, "a.hfpxzc").get_attribute("href")
data = {
"title": el.find_element(By.CSS_SELECTOR, ".qBF1Pd").text.strip(),
"avg_rating": el.find_element(By.CSS_SELECTOR, ".MW4etd").text.strip(),
"reviews": el.find_element(By.CSS_SELECTOR, ".UY7F9").text.replace("(", "").replace(")", "").strip(),
"address": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(1) > span:last-child").text.replace("·", "").strip(),
"description": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(2)").text.replace("·", "").strip(),
"website": el.find_element(By.CSS_SELECTOR, "a.lcr4fd").get_attribute("href"),
"category": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(1) > span:first-child").text.replace("·", "").strip(),
"timings": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(3) > span:first-child").text.replace("·", "").strip(),
"phone_num": el.find_element(By.CSS_SELECTOR, ".W4Efsd:last-child > .W4Efsd:nth-of-type(3) > span:last-child").text.replace("·", "").strip(),
"extra_services": el.find_element(By.CSS_SELECTOR, ".qty3Ue").text.replace("·", "").replace(" ", " ").strip(),
"latitude": link.split("!8m2!3d")[1].split("!4d")[0],
"longitude": link.split("!4d")[1].split("!16s")[0],
"link": link,
"dataId": link.split("1s")[1].split("!8m")[0],
}
maps_data.append(data)
return maps_data
def scroll_page(page, scroll_container, item_target_count):
items = []
previous_height = driver.execute_script(f"return document.querySelector('{scroll_container}').scrollHeight")
while len(items) < item_target_count:
items = extract_items(page)
driver.execute_script(f"document.querySelector('{scroll_container}').scrollTo(0, document.querySelector('{scroll_container}').scrollHeight)")
driver.execute_script(f"return document.querySelector('{scroll_container}').scrollHeight > {previous_height}")
time.sleep(2)
return items
def get_maps_data():
driver.get("https://www.google.com/maps/search/Starbucks/@26.8484046,75.7215344,12z/data=!3m1!4b1")
time.sleep(5)
data = scroll_page(driver, ".m6QErb[aria-label]", 2)
print(data)
driver.quit()
get_maps_data()
Our result should look like this 👇🏻:
[
{
title: 'STARBUCKS',
avg_rating: '4.6',
reviews: '3,643',
address: 'D-Block Fort Anandam Near Gaurav Tower, next to Mercedes showroom',
description: 'Iconic Seattle-based coffeehouse chain',
website: 'http://starbucks.in/',
category: 'Coffee shop',
timings: 'Open ⋅ Closes 12 am',
phone_num: '079765 62949',
extra_services: 'Dine-inTakeawayNo-contact delivery',
latitude: '26.8556211',
longitude: '75.8058191',
link: 'https://www.google.com/maps/place/STARBUCKS/data=!4m7!3m6!1s0x396db5631deeb72b:0xb06c14c4ce81e24a!8m2!3d26.8556211!4d75.8058191!16s%2Fg%2F11qg98xgt3!19sChIJK7fuHWO1bTkRSuKBzsQUbLA?authuser=0&hl=en&rclk=1',
dataId: '0x396db5631deeb72b:0xb06c14c4ce81e24a'
},
{
title: 'Starbucks Coffee',
avg_rating: '4.7',
reviews: '1,028',
address: 'Ground Floor, Near Naturals Icecream, A-5, C scheme chomu circle, Sardar Patel Marg',
description: 'Iconic Seattle-based coffeehouse chain',
website: 'https://www.starbucks.com/',
category: 'Coffee shop',
timings: 'Open ⋅ Closes 11 pm',
phone_num: '022 6611 3939',
extra_services: 'Dine-inTakeawayNo-contact delivery',
latitude: '26.9109303',
longitude: '75.7953463',
link: 'https://www.google.com/maps/place/Starbucks+Coffee/data=!4m7!3m6!1s0x396db577dcbbb503:0x6bc55ebbd466bfde!8m2!3d26.9109303!4d75.7953463!16s%2Fg%2F11q95t5shd!19sChIJA7W73He1bTkR3r9m1LtexWs?authuser=0&hl=en&rclk=1',
dataId: '0x396db577dcbbb503:0x6bc55ebbd466bfde'
},
......
Exporting Google Maps Data to CSV
Our last step would be to export the Google Maps Data to a CSV file. We will use the CSV library to convert this data into a CSV file.
import csv
Import this library and replace the console.log(data) statement with the below code.
with open(csv_file_path, mode="w", newline="") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(data)
print("CSV file created successfully:", csv_file_path)
Run this program in your terminal and you will get the CSV file google_maps.csv in your project folder.

So, this is how you can create a basic scraper to extract data from Google Maps. However, this solution is not scalable and is too time-consuming to perform large extraction. This problem can be easily solved by using Serpdog’s Google Maps API, which we will discuss shortly.
Advantages of Google Maps Scraping
Web Scraping Google Maps can provide you with various types of benefits:
Lead Generation — Scraping Google Maps can help you collect emails and phone numbers in large numbers from various places, and you can use them to create your database of leads that can sell at a high price in the market.
Sentimental Analysis — Google Maps data can be used for analyzing the sentiment of the public based on the average ratings and reviews given by the public.
Location-Based Services — One can scrape Google Maps data to provide services like finding nearby businesses, restaurants, pubs, and cafes based on the user’s location.
Limitations of using official Google Maps API
The official Google Maps is not considered an alternative due to several reasons:
Access Restrictions — The official Google Maps API has imposed restrictions on the number of requests you can hit per second to a limit of 100 only. These types of restrictions disallow extensive data extraction required for scraping purposes.
Limited Amount of Data — The Google Maps API returns structured data, but it is not as flexible and detailed compared to what other web scrapers provide in the market.
Cost Issues — Google Maps API can become a prohibitively costly solution for large-scale data extraction due to the usage-based pricing model, making it a non-feasible solution for developers.
Using Serpdog’s Google Maps Scraper
Creating your dedicated solution or relying solely on the official API might not be a long-term alternative as various limitations disallow extensive data scraping to collect vital data needed for further analysis.
However, Serpdog’s Google Maps API provides a robust and streamlined solution for businesses struggling to extract Google Maps data at scale. It provides several data points including contact numbers, customer reviews, and operating hours to its users to enrich their application or database with the most accurate and quality information.
It also provides free 100 credits to users on registration!!
After getting registered, you will be redirected to our dashboard, where you can find your API Key.
Integrate this API Key in the below code, and you will be able to web scrape Google Maps at a rapid speed without experiencing any blockage.
import requests
payload = {'api_key': 'APIKEY', 'q': 'coffee', 'll': '@40.7455096,-74.0083012,15.1z'}
resp = requests.get('https://api.serpdog.io/maps_search', params=payload)
print (resp.text)
Results:
"search_results": [
{
"title": "Gregorys Coffee",
"place_id": "ChIJQTNrM69ZwokR3ggxzgeelqQ",
"data_id": "0x89c259af336b3341:0xa4969e07ce3108de",
"data_cid": "-6586903648621492002",
"reviews_link": "https://api.serpdog.io/reviews?api_key=APIKEY&data_id=0x89c259af336b3341:0xa4969e07ce3108de",
"photos_link": "https://api.serpdog.io/maps_photos?api_key=APIKEY&data_id=0x89c259af336b3341:0xa4969e07ce3108de",
"posts_link": "https://api.serpdog.io/maps_post?api_key=APIKEY&data_id=0x89c259af336b3341:0xa4969e07ce3108de",
"gps_coordinates": {
"latitude": 40.7477283,
"longitude": -73.9890454
},
"provider_id": "/g/11xdfwq9f",
"rating": 4.1,
"reviews": 1153,
"price": "££",
"type": "Coffee shop",
"types": [
"Coffee shop"
],
"address": "874 6th Ave New York, NY 10001 United States",
"open_state": "Open ⋅ Closes 7 pm",
"hours": "Open ⋅ Closes 7 pm",
"operating_hours": {
"monday": "6:30 am–7 pm",
"tuesday": "6:30 am–7 pm",
"wednesday": "6:30 am–7 pm",
"thursday": "6:30 am–7 pm",
"friday": "6:30 am–7 pm",
"saturday": "7 am–7 pm",
"sunday": "7 am–7 pm"
},
"phone": "+1 877-231-7619",
"description": "House-roasted coffee, snacks & free WiFi Outpost of a chain of sleek coffeehouses offering house-roasted coffee, free WiFi & light bites.",
"thumbnail": "https://lh5.googleusercontent.com/p/AF1QipNq-8YRdAjiVW7uFMWDzHarqoK2Pr7bxIqI7t8A=w86-h114-k-no"
},
......
Conclusion:
In this tutorial, we learned to scrape Google Maps Results using Python. Feel free to message me if I missed something. Follow me on Twitter. Thanks for reading!