

Google is one of the great sources of images that can be used to create machine learning models such as image recognition, object detection, and much more.
In this article, we will discuss how to scrape Google Images with Python, using Serpdog’s Google Images API to harness the vast repository of images to integrate into our projects and applications.
Why scrape Google Images?
Scraping Google Images can be beneficial for several reasons:
Training Machine Learning Models — Machine Learning Models based on visual intelligence require a vast dataset of labeled images to search for the common patterns between them. Google Image has a huge repository of different types of images which can help these models learn and differentiate between the objects to increase their accuracy and efficiency.
Object Detection and Segmentation — Scraped image datasets can be used to train models for object detection and segmentation, enabling the accurate identification of objects or regions within the images, which can be used in tasks like medical image analysis, autonomous vehicle navigation, and surveillance systems.
Research and Analysis — Researchers and analysts can also use extracted image datasets to identify current trends and gain insights into various fields including fashion, design, architecture, and more.
Setting Up Our Scraper Using Google Images API
As we are using Serpdog’s Google Images API for this tutorial, it is important to register on our website to get the API credentials and some free credits before going ahead with the project.
This API will help us retrieve images faster without requiring any custom setup for our scraper.
Installation
Before getting started, don’t forget to install Python on your system.
Afterward, we will install the Requests library in Python to establish an HTTP connection with the API.pip install requests
To ensure all dependencies are installed in your project folder, run this command in your terminal.
Setup
Now that we’ve installed our required libraries, we’ll proceed by importing them to use them further in this tutorial.
import requests
import csv
CSV will be used to store the results in a CSV file.
Then, we will define the API endpoint, and parameters to fetch data from the Serpdog’s Google Images Scraper. You can also refer to this documentation, where you can get a variety of parameters to filter the image results according to your requirements.
url = "https://api.serpdog.io/images"
params = {
"api_key": "xxxxxxxxxxx6421",
"q": "water+coolers",
"gl": "us"
}
The first line defines the URL endpoint for the Images API where the GET request will be sent to fetch the images.
Next, we created a dictionary named “params” which consists of the parameters to be sent with the API request. Make sure to replace the API Key with the actual API Key you will get by registering on Serpdog.
Finally, we will use the requests library to extract the data.
response = requests.get(url, params=params)
You can print the data in the terminal or follow this tutorial further to get the data in the CSV file.
data = response.json()
image_results = data['image_results']
# Extract desired fields from each object
data_to_write = []
for item in image_results:
data_to_write.append({
'title': item['title'],
'image': item['image'],
'source': item['source'],
'original': item['original'],
'link': item['link']
})
# Write data to CSV file
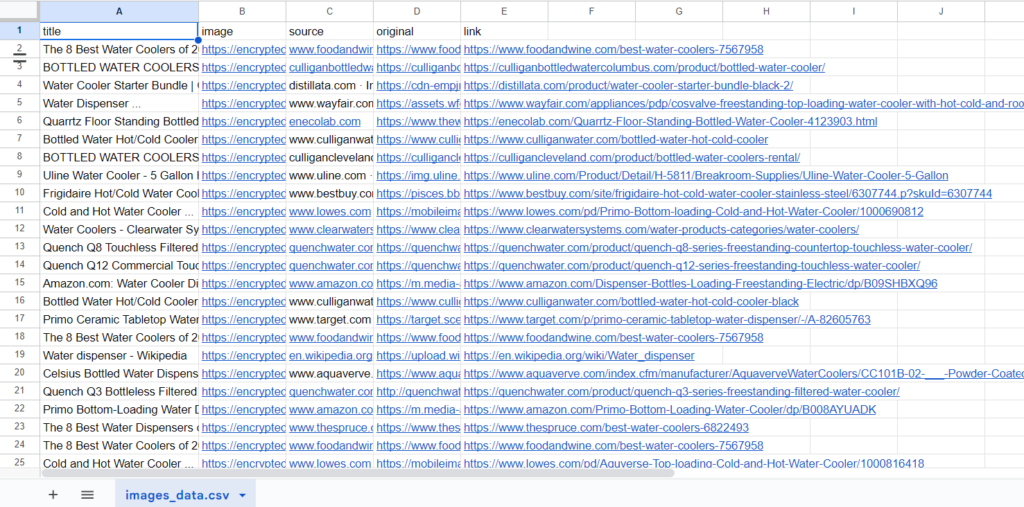
with open('images_data.csv', 'w', newline='', encoding='utf-8') as csv_file:
csv_writer = csv.DictWriter(csv_file, fieldnames=['title', 'image', 'source', 'original', 'link'])
csv_writer.writeheader()
csv_writer.writerows(data_to_write)
print('CSV file created successfully.')
First, we converted the obtained data from the API into JSON, and then we attempted to get the value of the key images_results from the data dictionary.
Finally, using the CSV library, we stored the data points of the image_results array in a CSV file.
Conclusion
In this article, we discussed how Google Images can be used for developing and training advanced machine-learning models based on visual intelligence. We also delve into the significance of Google Images in market research to identify current and potential future market trends. Additionally, we learned how Serpdog’s Google Images Scraper can serve as a strategic tool for extracting images at scale.
Feel free to message me anything you need clarification on. Follow me on Twitter. Thanks for reading!
Additional Resources
I have prepared a complete list of blogs on Google scraping, which can help you in your data extraction journey: