
Web Scraping is the process of automatically extracting a specific set of data from websites. It involves scraping the HTML data from the target website and parsing the HTML data to get structured desired data.
What if you want to do web scraping With JAVA?
If you were wondering how to do that, no worries! This guide will teach you how to set up your basic scraper to extract data using Java and store the data in a structured format.
Java is one of the most influential and popular languages in the world. With its support for multithreading, it simplifies and speeds up many tasks. Since its launch, Java’s performance has significantly improved, leading to its growing popularity and, most importantly, community support.
So, tighten your seatbelt and prepare for this long tutorial on web scraping with Java.
Why use Java For Web Scraping?
Web Scraping with Java offers you several benefits:
- Rich ecosystem — Java supports various libraries and frameworks that are compatible for performing web scraping tasks.
- Multithreading — Java is a multithreaded language that allows developers to scrape multiple web pages simultaneously.
- Performance —Java is a high-performance and scalable language that can easily and efficiently handle large amounts of data.
- Community Support — Java has large and active community support, which means you’re likely to find a solution for any error while performing a web scraping task.
It is always beneficial to keep some essential points in mind while using Java for large-scale web scraping:
- Use a cluster of residential and data center proxies to bypass any blockage for smooth scraping.
- Utilize an efficient system of libraries that can accelerate the scraping process and handle large amounts of data without any issues.
- Use a scalable Web Scraping API if it is becoming harder to manage the scraper.
Read More: Scrape Google Search Results With Java
Web Scraping Libraries in Java
There are several web scraping libraries in Java, but the two most used are:
HTMLUnit is a headless browser written in Java. It can perform various tasks like clicking links, submitting forms, etc. It can also be used to extract data from the web page.
JSOUP is a perfect web scraping library available in Java. It can be used for fetching the HTML using the connect() method, parsing by identifying the correct HTML tags and manipulating data rapidly and effectively.
In the next section, we will cover the practical utilization of these libraries in detail.
Let’s start Web Scraping With Java
In this tutorial, we are going to scrape this web page. We will extract the titles of all the products available on the website, and then our next step will be to display them within our program.

It is advisable to look for the HTML tags of the required elements to understand the structure of the HTML page before implementing your scraper into the program.
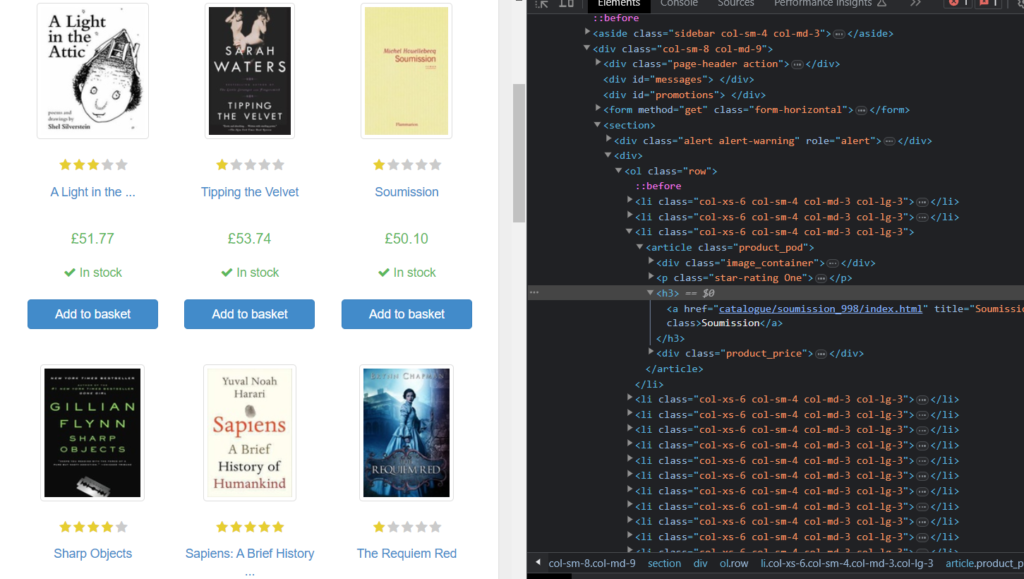
You can find the location of the title in HTML by right-clicking the mouse on any element present on the web page. A menu will open, from which you have to select the Inspect option.
There you can see the list of products with the tag li and class col-xs–6.
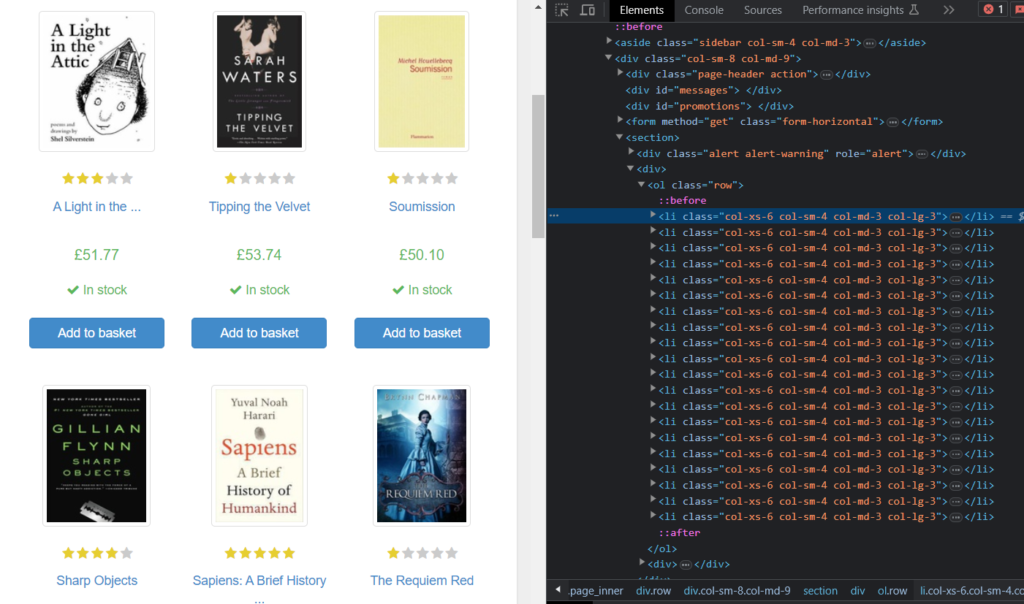
If you expand any of the list elements, you will get to know the location of the title in the list as h3.
Requirements
Before starting with the tutorial, I assume you have already set up the Java ecosystem within your device. If not, you can watch these videos:
For dependency management in Maven, you can read this guide.
HTMLUnit
To begin with HTMLUnit, I suggest adding this code to your pom.xml file.
<dependencies>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit-core-js</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.13.0</version>
</dependency>
</dependencies>
So, we have included all the dependencies we need for this project. It’s time we should look at the procedure of the program.
Process
First, we will define our target URL and then use HTMLUnit to create a new web client on a particular platform. You can also choose Mozilla, Safari, etc.
String url = "https://books.toscrape.com/";
// Create a new WebClient instance
WebClient webClient = new WebClient();
Next, we will use the web client to disable CSS and JS support. This is useful when you don’t have any specific needs for data from CSS and JS.
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
Then, we will retrieve the HTML content of the web page by using a class HtmlPage provided by HTMLUnit. This class also provides methods and properties for interacting with and manipulating HTML data.
HtmlPage page = webClient.getPage(url)
After that, we will select all the products with the respective class and tag, which we have discussed in the above section.
HtmlElement[] products = page.getBody().getElementsByAttribute("li", "class", "col-xs-6").toArray(new HtmlElement[0]);
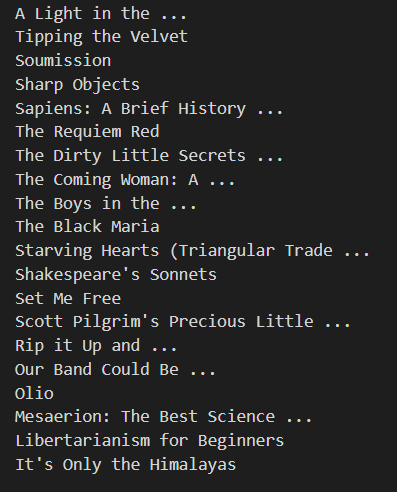
And finally, we will loop over this product array to extract all the titles.
int c = 0;
for (HtmlElement product : products) {
String title = product.getElementsByTagName("h3").get(0).asText();
System.out.println(title);
}
And don’t forget the last step to close the web client.
webClient.close();
Run this program in your terminal. You will the following output.
Jsoup
Let’s start web scraping with Jsoup by adding this dependency in pom.xml.
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Process
First, we will define our URL. Then, we will create a connection with the web page to extract the raw HTML data.
String url = "https://books.toscrape.com/";
// Fetch the web page content
Document doc = Jsoup.connect(url).get();
Then, we will select all the products on the web page using the select() method.
Elements products = doc.select("li.col-xs-6");
And finally, we will loop over all the products to extract all the titles and print them in the terminal.
for (Element product : products) {
String title = product.select("h3").first().text();
System.out.println(title);
}
Run this code. You will get the same output as we got in the above section.
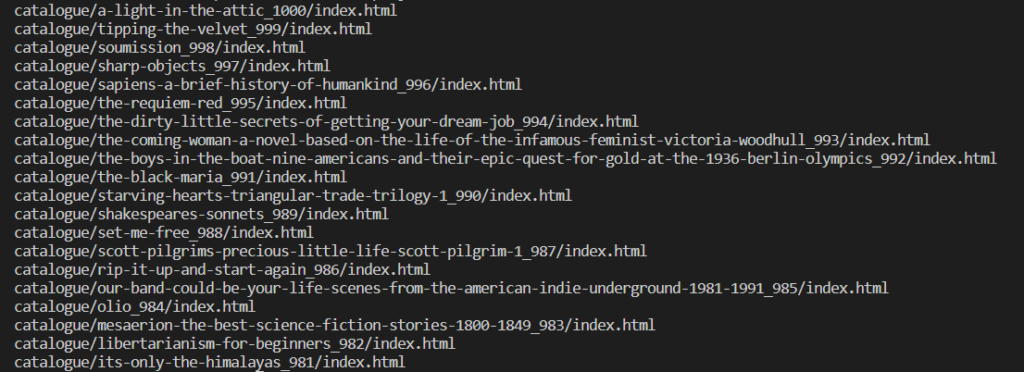
You can also use this code to extract the links of all the products. Make a minor change in the select() method, and then you are good to go!
for (Element product : products) {
String link = product.select("a").attr("href");
System.out.println(link);
}
Cons of Using Java For Web Scraping
While Java is a great and scalable language, it also has some associated drawbacks.
Learning curve — Java has a steeper learning curve and can be more challenging to understand for beginners than languages like Python and JavaScript.
Boilerplate code —A small scraping task in Java can require more lines of code compared to other languages, making data extraction more time-consuming and CPU-intensive.
Unmatured ecosystem — Despite having various web scraping libraries, the web scraping ecosystem is still unmatured in Java. Scraping dynamically rendered content, which can be achieved quickly with JavaScript and Python, may require more effort in Java.
Conclusion
In this tutorial, we learned to develop a basic understanding of web scraping with Java. We also got familiar with some cons associated with Java, such as the steeper learning curve, boilerplate code, and an unmatured ecosystem.
While JSoup can be used for scraping statically rendered content, it has limitations while scraping dynamically rendered content. In such cases, you may need to utilize tools like Selenium or Puppeteer to retrieve the desired data from the website.
Please do not hesitate to message me if I missed something. If you think we can complete your custom scraping projects, feel free to contact us.
Follow me on Twitter. Thanks for reading!
Frequently Asked Questions
Is Java good for web scraping?
Java stands as a strong choice for web scraping due to its array of powerful libraries such as HTMLUnit and JSOUP, designed to simplify the complexity and enhance the efficiency of data scraping processes.
Is web scraping easier with Java Or Python?
Python has several advantages over Java. Its clear and simple syntax facilitates a quick and effective understanding for beginners. Additionally, it boasts a range of libraries like Scrapy and BS4, tailored explicitly for web scraping.
Additional Resources
Want to learn more about web scraping?
No worries! We have prepared a complete list of tutorials so you can get comfortable while creating your web scraping projects.