
Google Scholar data can be a great choice for businesses that specifically want to access quality research-based content available on the internet.
In this tutorial, we will learn to scrape Google Scholar Results using Python and libraries requests and BeautifulSoup.
Let’s start scraping Google Scholar using Python
In this section, we will prepare a basic script using Python to scrape Google Scholar Results, but let us first complete the requirements of this project.
Python Installation
If you have not already installed Python on your device, please consider these videos:
Or you can directly install Python from their official website.
Requirements
To scrape Google Scholar Results, we will be using these two Python libraries:
- Beautiful Soup — Used for parsing the raw HTML data.
- Requests — Used for making HTTP requests.
You can run the below commands in your project terminal to install the libraries.
pip install requests
pip install beautifulsoup4
Code Setup
Create a new file in your project folder and import these installed libraries.
import requests
from bs4 import BeautifulSoup
After importing the libraries, we will create a basic function to extract the scholarly data. We will set up the code for API requests using the library we have installed above.
def getScholarData():
try:
url = "target_url"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.361681261652"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
After making the API request, we created an instance of BeautifulSoup to parse the HTML.
For the URL variable, you can select any Google Scholar Search URL. Otherwise, we will be defining it in a bit.
Google Scholar Organic Results
In this section, we will scrape the organic results from Google Scholar.

Open this link on your desktop. This link will serve as our target URL for this section. This completes the first part of retrieving the HTML and preparing to parse it.
import requests
from bs4 import BeautifulSoup
def getScholarData():
try:
url = "https://www.google.com/scholar?q=Quantum+Physics&hl=en"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
Right-click on the first result; this action will open a menu. Scroll to the bottom of the menu and click on the “Inspect” option.

After observing the structure of the HTML, you will get to know that each result is wrapped under the div tag with the classes .gs_r gs_or gs_scl.
We will select the first class from the above options to loop over every result on the page.
scholar_results = []
for el in soup.select(".gs_r"):
Now, we will locate the tags for the title, link, and article ID. Right-click on the title of the first result, and inspect it, you will find both the title and the link which is also present under it.
for el in soup.select(".gs_r"):
scholar_results.append({
"title": el.select(".gs_rt")[0].text,
"title_link": el.select(".gs_rt a")[0]["href"],
In the same anchor tag, we have an ID attribute which we will use to extract the article ID.
"id": el.select(".gs_rt a")[0]["id"],
Similarly, we can find the other data entities. At last, we will put the complete parser, and append it to the scholar results array. Feel free to make any changes if you want.
for el in soup.select(".gs_r"):
scholar_results.append({
"title": el.select(".gs_rt")[0].text,
"title_link": el.select(".gs_rt a")[0]["href"],
"id": el.select(".gs_rt a")[0]["id"],
"displayed_link": el.select(".gs_a")[0].text,
"snippet": el.select(".gs_rs")[0].text.replace("\n", ""),
"cited_by_count": el.select(".gs_nph+ a")[0].text,
"cited_link": "https://scholar.google.com" + el.select(".gs_nph+ a")[0]["href"],
"versions_count": el.select("a~ a+ .gs_nph")[0].text,
"versions_link": "https://scholar.google.com" + el.select("a~ a+ .gs_nph")[0]["href"] if el.select("a~ a+ .gs_nph")[0].text else "",
})
Finally, we will put the complete code for the function to get data from the Google Scholar Web Page.
import requests
from bs4 import BeautifulSoup
def getScholarData():
try:
url = "https://www.google.com/scholar?q=Quantum+Physics&hl=en"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
scholar_results = []
for el in soup.select(".gs_r"):
scholar_results.append({
"title": el.select(".gs_rt")[0].text,
"title_link": el.select(".gs_rt a")[0]["href"],
"id": el.select(".gs_rt a")[0]["id"],
"displayed_link": el.select(".gs_a")[0].text,
"snippet": el.select(".gs_rs")[0].text.replace("\n", ""),
"cited_by_count": el.select(".gs_nph+ a")[0].text,
"cited_link": "https://scholar.google.com" + el.select(".gs_nph+ a")[0]["href"],
"versions_count": el.select("a~ a+ .gs_nph")[0].text,
"versions_link": "https://scholar.google.com" + el.select("a~ a+ .gs_nph")[0]["href"] if el.select("a~ a+ .gs_nph")[0].text else "",
})
for i in range(len(scholar_results)):
scholar_results[i] = {key: value for key, value in scholar_results[i].items() if value != "" and value is not None}
print(scholar_results)
except Exception as e:
print(e)
getScholarData()
This will return the following data from the web page:
[
{
title: '[BOOK][B] Quantum physics',
title_link: 'https://books.google.com/books?hl=en&lr=&id=hBlZu4M51IMC&oi=fnd&pg=PA561&dq=Quantum+Physics&ots=uFlw7JwreV&sig=WDlW9BK6r4fYkOfC-0CZcydSZGw',
id: 'ENaNHF5MoQsJ',
displayed_link: 'M Le Bellac - 2011 - books.google.com',
snippet: 'Quantum physics allows us to understand the nature of the … In Quantum Physics, Le Bellac provides a thoroughly … Bellac teaches the fundamentals of quantum physics using an original …',
cited_by_count: 'Cited by 237',
cited_link: 'https://scholar.google.com/scholar?cites=838034972757317136&as_sdt=2005&sciodt=0,5&hl=en',
versions_count: 'All 5 versions',
versions_link: 'https://scholar.google.com/scholar?cluster=838034972757317136&hl=en&as_sdt=0,5'
},
{
title: '[BOOK][B] Quantum physics',
title_link: 'https://books.google.com/books?hl=en&lr=&id=qFtQiVmjWUEC&oi=fnd&pg=PA28&dq=Quantum+Physics&ots=tvyRLMCMgo&sig=M61e-yrPNyUA0kgpokfdb-LR3nw',
id: 'cU32d0ZoSA0J',
displayed_link: 'S Gasiorowicz - 2007 - books.google.com',
snippet: '… the Old Quantum Theory. This material appears in every textbook on modern physics in one … the creation of quantum mechanics, and it highlights the differences between classical and …',
cited_by_count: 'Cited by 1452',
cited_link: 'https://scholar.google.com/scholar?cites=957129572685860209&as_sdt=2005&sciodt=0,5&hl=en',
versions_count: 'All 10 versions',
versions_link: 'https://scholar.google.com/scholar?cluster=957129572685860209&hl=en&as_sdt=0,5'
},
.....
Google Scholar Cite Results
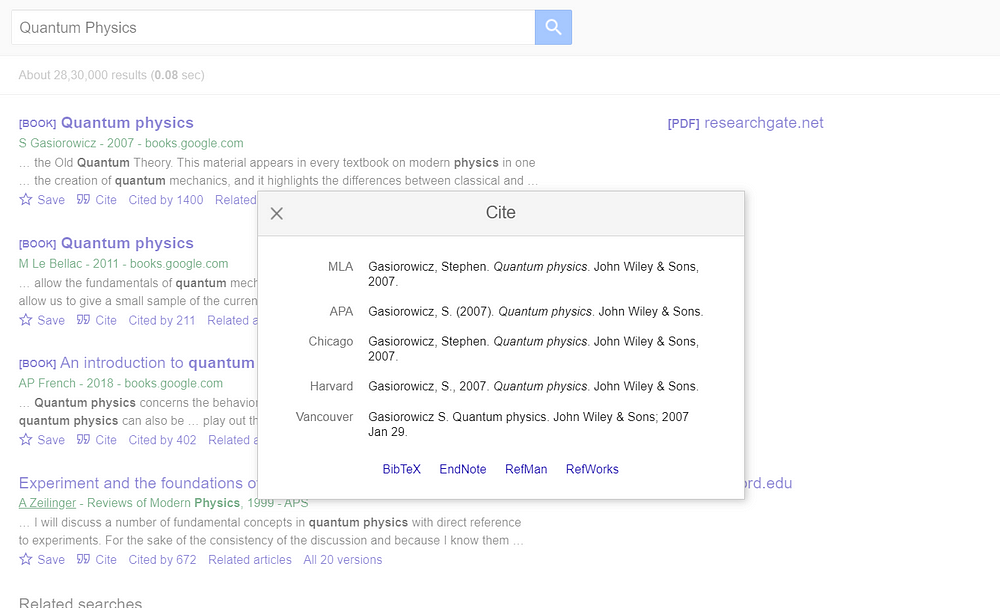
Then, we will use the IDs we got from scraping organic results to scrape the cite results.
import requests
from bs4 import BeautifulSoup
def getData():
try:
url = "https://scholar.google.com/scholar?q=info:cU32d0ZoSA0J:scholar.google.com&output=cite"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
cite_results = []
for el in soup.select("#gs_citt tr"):
cite_results.append({
"title": el.select_one(".gs_cith").text.strip(),
"snippet": el.select_one(".gs_citr").text.strip()
})
links = []
for el in soup.select("#gs_citi .gs_citi"):
links.append({
"name": el.text.strip(),
"link": el.get("href")
})
print(cite_results)
print(links)
except Exception as e:
print(e)
getData()
If you look at the URL, after the info we have used an ID of the first organic result we got from the above section.
Our result should look like this:
[
{
'title': 'MLA', 'snippet': 'Gasiorowicz, Stephen. Quantum physics. John Wiley & Sons, 2007.'
},
{
'title': 'APA', 'snippet': 'Gasiorowicz, S. (2007). Quantum physics. John Wiley & Sons.'
},
{
'title': 'Chicago', 'snippet': 'Gasiorowicz, Stephen. Quantum physics. John Wiley & Sons, 2007.'
},
{
'title': 'Harvard', 'snippet': 'Gasiorowicz, S., 2007. Quantum physics. John Wiley & Sons.'
},
{
'title': 'Vancouver', 'snippet': 'Gasiorowicz S. Quantum physics. John Wiley & Sons; 2007 Jan 29.'
}
]
[
{
'name': 'BibTeX',
'link': 'https: //scholar.googleusercontent.com/scholar.bib?q=info:cU32d0ZoSA0J:scholar.google.com/&output=citation&scisdr=Cm3wRhgwGAA:AGlGAw8AAAAAZFe6DtNdVceWMhOLx32wQFKpqxA&scisig=AGlGAw8AAAAAZFe6DjCj95cYqQaVYG2_H2xJMDY&scisf=4&ct=citation&cd=-1&hl=en'
},
{
'name': 'EndNote',
'link': 'https://scholar.googleusercontent.com/scholar.enw?q=info:cU32d0ZoSA0J:scholar.google.com/&output=citation&scisdr=Cm3wRhgwGAA:AGlGAw8AAAAAZFe6DtNdVceWMhOLx32wQFKpqxA&scisig=AGlGAw8AAAAAZFe6DjCj95cYqQaVYG2_H2xJMDY&scisf=3&ct=citation&cd=-1&hl=en'
},
{
'name': 'RefMan',
'link': 'https://scholar.googleusercontent.com/scholar.ris?q=info:cU32d0ZoSA0J:scholar.google.com/&output=citation&scisdr=Cm3wRhgwGAA:AGlGAw8AAAAAZFe6DtNdVceWMhOLx32wQFKpqxA&scisig=AGlGAw8AAAAAZFe6DjCj95cYqQaVYG2_H2xJMDY&scisf=2&ct=citation&cd=-1&hl=en'
},
{
'name': 'RefWorks',
'link': 'https://scholar.googleusercontent.com/scholar.rfw?q=info:cU32d0ZoSA0J:scholar.google.com/&output=citation&scisdr=Cm3wRhgwGAA:AGlGAw8AAAAAZFe6DtNdVceWMhOLx32wQFKpqxA&scisig=AGlGAw8AAAAAZFe6DjCj95cYqQaVYG2_H2xJMDY&scisf=1&ct=citation&cd=-1&hl=en'
}
]
Google Scholar Authors
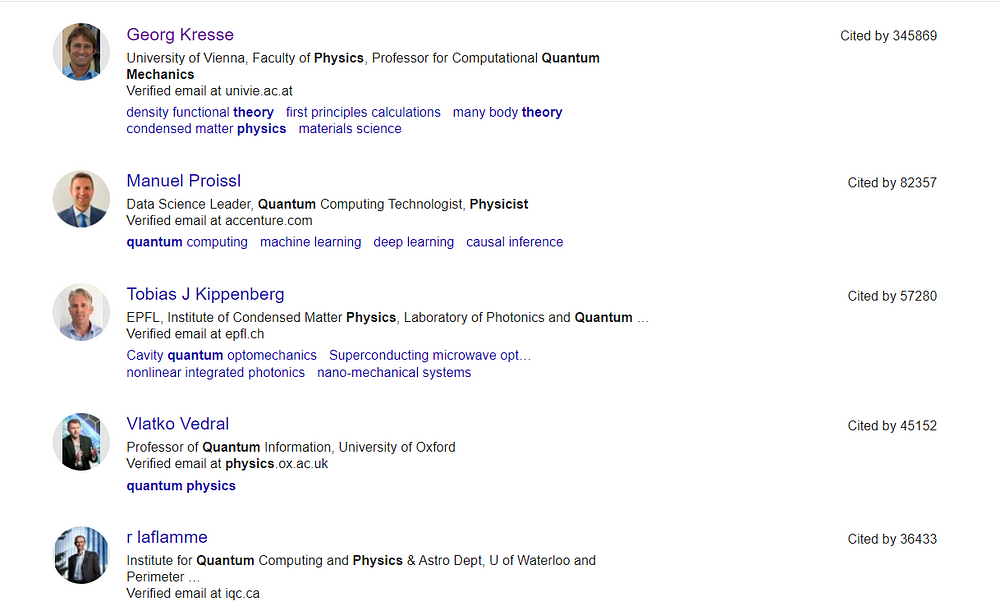
Now, let’s scrape the profiles of the authors who have published quality content on Quantum Physics.
Here is our code:
import requests
from bs4 import BeautifulSoup
def getScholarProfiles():
try:
url = "https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=Quantum+Physics"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
scholar_profiles = []
for el in soup.select('.gsc_1usr'):
profile = {
'name': el.select_one('.gs_ai_name').get_text(),
'name_link': 'https://scholar.google.com' + el.select_one('.gs_ai_name a')['href'],
'position': el.select_one('.gs_ai_aff').get_text(),
'email': el.select_one('.gs_ai_eml').get_text(),
'departments': el.select_one('.gs_ai_int').get_text(),
'cited_by_count': el.select_one('.gs_ai_cby').get_text().split(' ')[2]
}
scholar_profiles.append({k: v for k, v in profile.items() if v})
print(scholar_profiles)
except Exception as e:
print(e)
getScholarProfiles()
Our results should look like this:
[
{
name: 'Georg Kresse',
name_link: 'https://scholar.google.com/citations?hl=en&user=Pn8ouvAAAAAJ',
position: 'University of Vienna, Faculty of Physics, Professor for Computational Quantum Mechanics',
email: 'Verified email at univie.ac.at',
departments: 'density functional theory first principles calculations many body theory condensed matter physics materials science ',
cited_by_count: '345869'
},
{
name: 'Manuel Proissl',
name_link: 'https://scholar.google.com/citations?hl=en&user=ikHSFIkAAAAJ',
position: 'Data Science Leader, Quantum Computing Technologist, Physicist',
email: 'Verified email at accenture.com',
departments: 'quantum computing machine learning deep learning causal inference ',
cited_by_count: '82357'
},
....
Google Scholar Author Profile
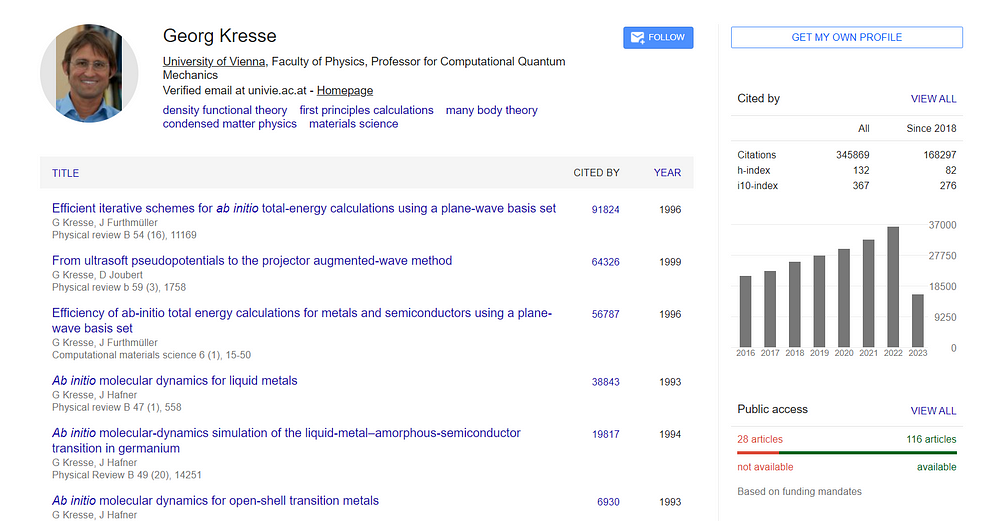
Now, let us create a scraper to extract data from Google Author Profile.
First, we will extract some main details about the author and then move to its published content.

import requests
from bs4 import BeautifulSoup
def getAuthorProfileData():
try:
url = "https://scholar.google.com/citations?hl=en&user=Pn8ouvAAAAAJ"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36"
}
response = requests.get(url, headers=headers)
print(response.status_code)
soup = BeautifulSoup(response.text, 'html.parser')
author_results = {}
author_results['name'] = soup.select_one("#gsc_prf_in").get_text()
author_results['position'] = soup.select_one("#gsc_prf_inw+ .gsc_prf_il").text
author_results['email'] = soup.select_one("#gsc_prf_ivh").text
author_results['published_content'] = soup.select_one("#gsc_prf_int").text
print(author_results)
except Exception as e:
print(e)
getAuthorProfileData()
Our result should look like this:
{
name: 'Georg Kresse',
position: 'University of Vienna, Faculty of Physics, Professor for Computational Quantum Mechanics',
email: 'Verified email at univie.ac.at - Homepage',
published_content: 'density functional theoryfirst principles calculationsmany body theorycondensed matter physicsmaterials science'
}
Then, we will scrape the content published by the author.

Here is our code:
for el in soup.select("#gsc_a_b .gsc_a_t"):
article = {
'title': el.select_one(".gsc_a_at").text,
'link': "https://scholar.google.com" + el.select_one(".gsc_a_at")['href'],
'authors': el.select_one(".gsc_a_at+ .gs_gray").text,
'publication': el.select_one(".gs_gray+ .gs_gray").text
}
articles.append(article)
for i in range(len(articles)):
articles[i] = {k: v for k, v in articles[i].items() if v and v != ""}
And the results should look like this:
[
{
title: 'Efficient iterative schemes for ab initio total-energy calculations using a plane-wave basis set',
link: 'https://scholar.google.com/citations?view_op=view_citation&hl=en&user=Pn8ouvAAAAAJ&citation_for_view=Pn8ouvAAAAAJ:a3BOlSfXSfwC',
authors: 'G Kresse, J Furthmüller',
publication: 'Physical review B 54 (16), 11169, 1996'
},
{
title: 'From ultrasoft pseudopotentials to the projector augmented-wave method',
link: 'https://scholar.google.com/citations?view_op=view_citation&hl=en&user=Pn8ouvAAAAAJ&citation_for_view=Pn8ouvAAAAAJ:F9fV5C73w3QC',
authors: 'G Kresse, D Joubert',
publication: 'Physical review b 59 (3), 1758, 1999'
},
Now, we will scrape the Google Scholar Author profile Cited By results in which we will cover citation, h-index, and the i10-index since 2017.
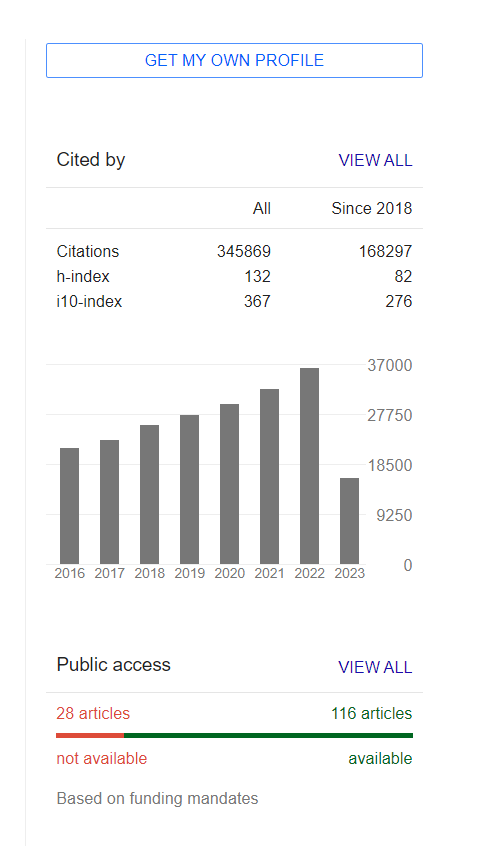
Here is the code:
cited_by = {}
cited_by['table'] = []
cited_by['table'].append({})
cited_by['table'][0]['citations'] = {}
cited_by['table'][0]['citations']['all'] = soup.select_one("tr:nth-child(1) .gsc_rsb_sc1+ .gsc_rsb_std").text
cited_by['table'][0]['citations']['since_2017'] = soup.select_one("tr:nth-child(1) .gsc_rsb_std+ .gsc_rsb_std").text
cited_by['table'].append({})
cited_by['table'][1]['h_index'] = {}
cited_by['table'][1]['h_index']['all'] = soup.select_one("tr:nth-child(2) .gsc_rsb_sc1+ .gsc_rsb_std").text
cited_by['table'][1]['h_index']['since_2017'] = soup.select_one("tr:nth-child(2) .gsc_rsb_std+ .gsc_rsb_std").text
cited_by['table'].append({})
cited_by['table'][2]['i_index'] = {}
cited_by['table'][2]['i_index']['all'] = soup.select_one("tr~ tr+ tr .gsc_rsb_sc1+ .gsc_rsb_std").text
cited_by['table'][2]['i_index']['since_2017'] = soup.select_one("tr~ tr+ tr .gsc_rsb_std+ .gsc_rsb_std").text
Here are the results:
[
{ citations: { all: '345869', since_2017: '168297' } },
{ h_index: { all: '132', since_2017: '82' } },
{ i_index: { all: '367', since_2017: '276' } }
]
Here is the complete code to scrape the complete profile of an Author:
import requests
from bs4 import BeautifulSoup
def getAuthorProfileData():
try:
url = "https://scholar.google.com/citations?hl=en&user=cOsxSDEAAAAJ"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
author_results = {}
articles = []
author_results['name'] = soup.select_one("#gsc_prf_in").text
author_results['position'] = soup.select_one("#gsc_prf_inw+ .gsc_prf_il").text
author_results['email'] = soup.select_one("#gsc_prf_ivh").text
author_results['departments'] = soup.select_one("#gsc_prf_int").text
for el in soup.select("#gsc_a_b .gsc_a_t"):
article = {
'title': el.select_one(".gsc_a_at").text,
'link': "https://scholar.google.com" + el.select_one(".gsc_a_at")['href'],
'authors': el.select_one(".gsc_a_at+ .gs_gray").text,
'publication': el.select_one(".gs_gray+ .gs_gray").text
}
articles.append(article)
for i in range(len(articles)):
articles[i] = {k: v for k, v in articles[i].items() if v and v != ""}
cited_by = {}
cited_by['table'] = []
cited_by['table'].append({})
cited_by['table'][0]['citations'] = {}
cited_by['table'][0]['citations']['all'] = soup.select_one("tr:nth-child(1) .gsc_rsb_sc1+ .gsc_rsb_std").text
cited_by['table'][0]['citations']['since_2017'] = soup.select_one("tr:nth-child(1) .gsc_rsb_std+ .gsc_rsb_std").text
cited_by['table'].append({})
cited_by['table'][1]['h_index'] = {}
cited_by['table'][1]['h_index']['all'] = soup.select_one("tr:nth-child(2) .gsc_rsb_sc1+ .gsc_rsb_std").text
cited_by['table'][1]['h_index']['since_2017'] = soup.select_one("tr:nth-child(2) .gsc_rsb_std+ .gsc_rsb_std").text
cited_by['table'].append({})
cited_by['table'][2]['i_index'] = {}
cited_by['table'][2]['i_index']['all'] = soup.select_one("tr~ tr+ tr .gsc_rsb_sc1+ .gsc_rsb_std").text
cited_by['table'][2]['i_index']['since_2017'] = soup.select_one("tr~ tr+ tr .gsc_rsb_std+ .gsc_rsb_std").text
print(author_results)
print(articles)
print(cited_by['table'])
except Exception as e:
print(e)
getAuthorProfileData()
Using Serpdog’s Google Scholar API for scraping Scholar Data
Scraping Google Scholar can be difficult for a developer with frequent blockage from Google. Also, one has to maintain the scraper accordingly with the changing HTML structure.
Suppose you were provided with a straightforward and efficient solution to scrape Google Scholar Results, wouldn’t that be an excellent choice?
Yes, you heard right! Our Google Scholar API allows businesses to scrape educational content from Google Scholar at scale using our powerful API infrastructure which is powered by a massive pool of 10M+ residential proxies.
We also offer 100 free requests on the first sign-up.
After getting registered on our website, you will get an API Key. Embed this API Key in the below code, you will be able to scrape Google Scholar Results at a much faster speed.
import requests
payload = {'api_key': 'APIKEY', 'q':'quantum+physics'}
resp = requests.get('https://api.serpdog.io/scholar', params=payload)
print (resp.text)
Conclusion
This tutorial taught us to scrape Google Scholar using Python. Feel free to message me if I missed something or if anything you need clarification on. Follow me on Twitter. Thanks for reading!