
The Python programming language was developed in 1991 by Guido van Rossum, mainly emphasizing code readability and clear and concise syntax.
Python has gained vast popularity in the web scraping community due to advantages like readability, scalability, etc. This makes it a great alternative to other programming languages and a perfect choice for web scraping tasks.
This blog post will not only focus on scraping Google but also provide you with a clear understanding of why Python is the best choice for extracting data from Google and what are the benefits of collecting information from Google.
We are going to use HTTPX and BS4 for scraping and parsing the raw HTML data.
By the end of this article, you will have a basic understanding of scraping Google Search Results with Python. You can also leverage this knowledge for future web scraping projects with other programming languages.
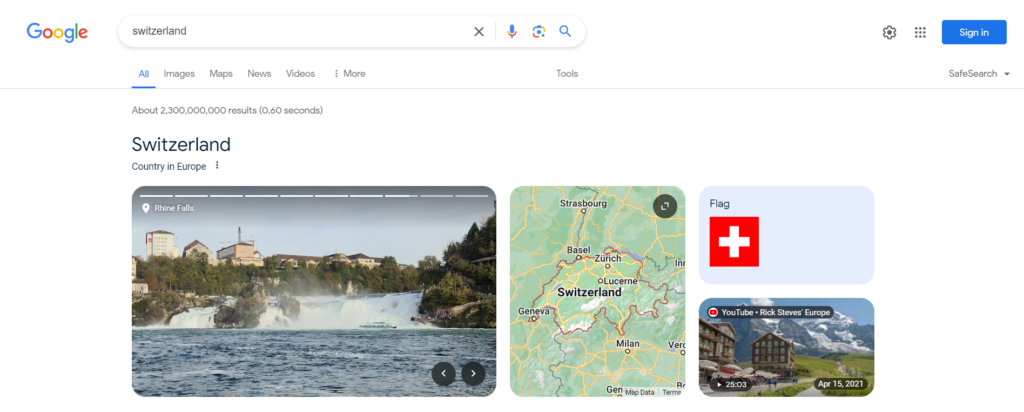
What are Google Search Results?
Google Search Results are the listings displayed on the search engine page for a particular query entered in the search bar. These results often include organic search results, knowledge graphs, “People Also Asked” sections, news articles, and other relevant content depending on the user’s query. Recently, Google has also added search results powered by generative AI, marking a significant revolution in how search results are displayed, providing a comprehensive and summarized combination of outputs for users’ queries.
Why Python for Scraping Google?
Python is a robust and powerful language that has given great importance to its code readability and clarity. This enables beginners to learn and implement scraping scripts quickly and easily. It also has a large and active community of developers who can help you in case of any problem in your code.
Another advantage of using Python is that it offers a wide range of frameworks and libraries specifically designed for scraping data from the web, including Scrapy, BeautifulSoup, Playwright, and Selenium.
Python offers numerous advantages like high performance, scalability, and various other scraping resources. This makes it stand as an excellent choice for not only extracting data from Google but also for other web scraping tasks.
Read More: The Top Preferred Languages For Web Scraping
Scraping Google Search Results Using SERP API
Let’s get started and collect data from Google SERP!
Set-Up
For those users who have not installed Python on their devices, please consider these videos:
If you don’t want to watch videos, you can directly install Python from their official website.
Installing Libraries
Now, let’s install the necessary libraries for this project in our folder.
- Beautiful Soup — A third-party library to parse the extracted HTML from the websites.
- Requests — A fully featured HTTP client for Python to extract data from websites.
If you don’t want to read their documentation, install these two libraries by running the below commands.
pip install requests
pip install beautifulsoup4
Getting API Credentials From Serpdog’s Google SERP API
To fetch data from Google SERP, we also need API credentials from Serpdog’s Google Search API.
After completing the registration process, you will be redirected to the dashboard where you will get your API Key.
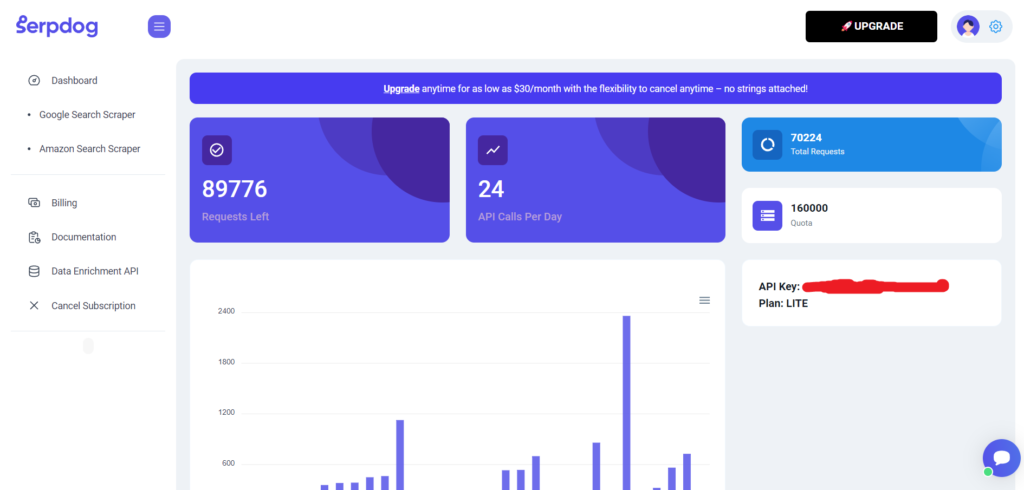
Setting Up our code for scraping search results
Create a new file in your project folder and paste the below code to import the libraries.
import requests
from bs4 import BeautifulSoup
Then, we will define an API URL to get results for the search query “sushi”.
import requests
payload = {'api_key': 'APIKEY', 'q':'sushi' , 'gl':'us'}
resp = requests.get('https://api.serpdog.io/search', params=payload)
print (resp.text)
You can also try to look at different queries instead of “sushi”. To integrate more parameters with the API, you can read our detailed documentation on using Serpdog’s Google Search API.
Run this program in your terminal, and you should get the results like this.
{
"meta": {
"api_key": "APIKEY",
"q": "sushi",
"gl": "us"
},
"user_credits_info": {
"quota": 160000,
"requests": 70245,
"requests_left": 89755
},
"search_information": {
"total_results": "About 889,000,000 results (0.25 seconds)",
"query_displayed": "sushi"
},
"menu_items": [
{
"title": "Maps",
"link": "https://maps.google.com/maps?sca_esv=f0f6d5f05aa680dc&gl=us&hl=en&output=search&q=sushi&source=lnms&entry=mc&ved=1t:200715&ictx=111",
"position": 1
},
{
"title": "Shopping",
"link": "https://www.google.com/search?sca_esv=f0f6d5f05aa680dc&gl=us&hl=en&q=sushi&tbm=shop&source=lnms&prmd=imsvnbtz&ved=1t:200715&ictx=111",
"position": 2
},
{
"title": "Videos",
"link": "https://www.google.com/search?sca_esv=f0f6d5f05aa680dc&gl=us&hl=en&q=sushi&tbm=vid&source=lnms&prmd=imsvnbtz&sa=X&ved=2ahUKEwiBlNbfpbKFAxWskokEHcigCGsQ0pQJegQIDBAB",
"position": 3
}
],
.......
}
As you can see, we have received the meta-information, which includes the parameters we passed with the API URL. We have also received user credit information, search information, menu items, and much more. I am unable to show the complete response here, as it is too large for the blog.
For instance, if we want only particular entities like organic results, and knowledge graphs and people also ask, then this can be done like this.
data = resp.json()
print(data["organic_results"])
print(data["knowledge_graph"])
print(data["peopleAlsoAskedFor"])
Implementing Pagination in the Scraper
Using the code above, we obtained the first 10 search results. However, if we want more, we can use the page or num parameter from the Google Search API documentation.
page
The page number to get targeted search results. (Enter 10 for 2nd-page results, 20 for 3rd, etc .)
num
Number of results per page. (Enter 10 for 10 results, 20 for 20 results, 30 for 30 results etc.)
For example, the following code will get you 10 results from the second page.
import requests
payload = {'api_key': 'APIKEY', 'q':'sushi' , 'gl':'us', 'page': '10'}
resp = requests.get('https://api.serpdog.io/search', params=payload)
print (resp.text)
However, if you want to save time, you can simply run the API request with a ‘num’ value of 100 to get 100 results at once.
import requests
payload = {'api_key': 'APIKEY', 'q':'sushi' , 'gl':'us', 'num': '100'}
resp = requests.get('https://api.serpdog.io/search', params=payload)
print (resp.text)
This will not cost you extra credits and will even return you with more volume of results.
Export scraped data to a CSV
To convert the obtained data into CSV, we will use the CSV library in Python. We’ll extract the title, link, and snippet from the organic results and store them in a corresponding CSV file.
import requests
import csv
payload = {'api_key': 'APIKEY', 'q':'sushi' , 'gl':'us', 'num': '10'}
resp = requests.get('https://api.serpdog.io/search', params=payload)
data = resp.json()
with open('search_results.csv', 'w', newline='') as csvfile:
csv_writer = csv.writer(csvfile)
# Write the headers
csv_writer.writerow(["Title", "Link", "Snippet"])
# Write the data
for result in data["organic_results"]:
csv_writer.writerow([result["title"], result["link"], result["snippet"]])
print('Done writing to CSV file.')
After running this program, a CSV file containing search results will be saved in your project folder.

Scraping Google Search Results Using Python and BS4
We have tried the automated method. However, it is also important to know the basics behind this method. We will now create a custom scraper using Python and BeautifulSoup to get those search results.
Firstly, install these two libraries by running the below commands.
If you don’t want to read their documentation, install these two libraries by running the below commands.
pip install requests
pip install beautifulsoup4
Process
So, we have completed the setup of our Python project for scraping Google. Let us first import the libraries we will use further in this tutorial.
import requests
from bs4 import BeautifulSoup
Then, we will set the headers to make our scraping bot mimic an organic user.
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4703.0 Safari/537.36"
}
response = requests.get("https://www.google.com/search?q=python+tutorial&gl=us&hl=en", headers=headers)
User Agent is a request header that identifies the device requesting the software.
Refer to this guide if you want to learn more about headers: Web Scraping With Python
After defining the headers, we used the requests library to create an HTTP GET connection on the Google search URL.
Then, we will create a BeautifulSoup object to parse and navigate through the HTML.
soup = BeautifulSoup(response.content, "html.parser")
After creating the Beautiful Soup object, we will locate the tags for the required elements from the HTML.
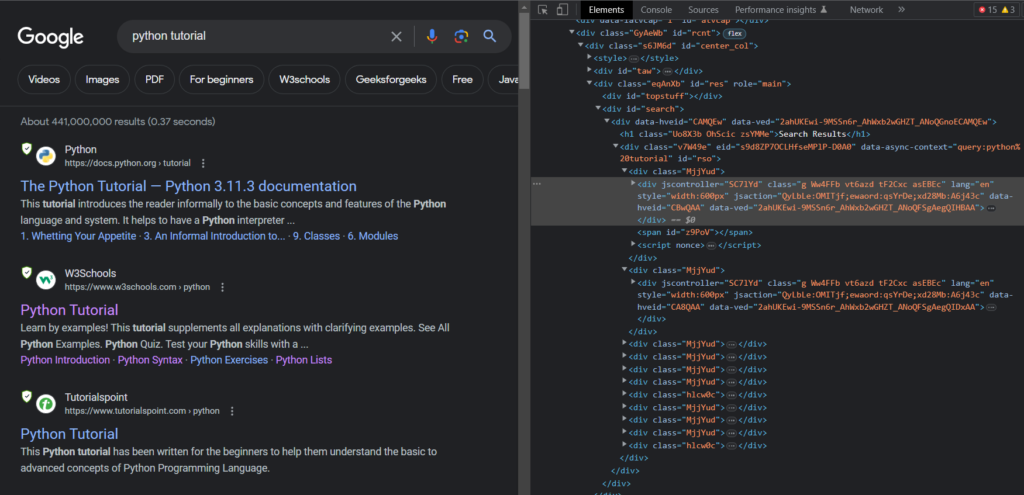
If you inspect the webpage, you will get to know that every organic result is under the div container with class g.
So, we will loop over every div having class g to get the required information from the HTML.
organic_results = []
i = 0
for el in soup.select(".g"):
organic_results.append({
})
i += 1
Then, we will locate the tags for the title, description, and link.
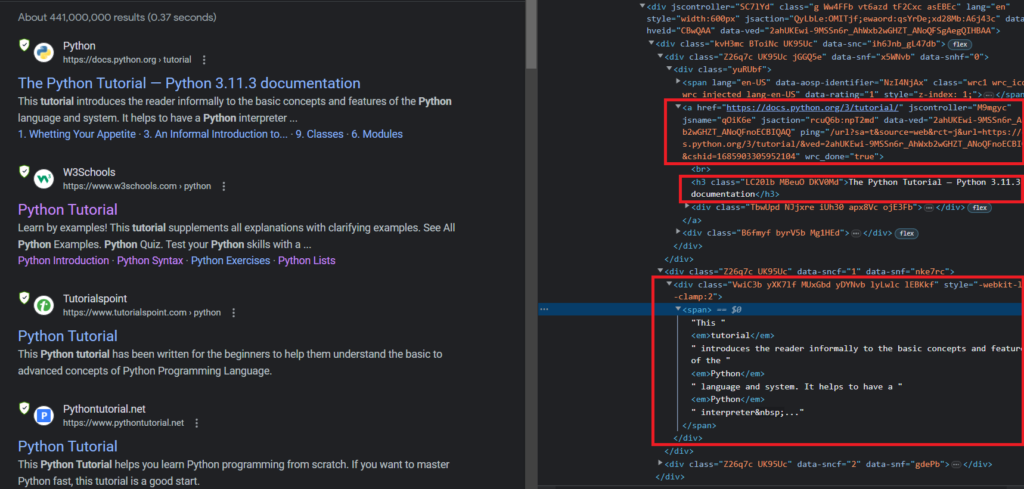
If you further inspect the HTML, or if you take a look at the above image, you will find that the tag for the title is h3, the tag for the link is .yuRUbf > a and the tag for the description is .VwiC3b.
organic_results = []
i = 0
for el in soup.select(".g"):
organic_results.append({
"title": el.select_one("h3").text,
"link": el.select_one(".yuRUbf > a")["href"],
"description": el.select_one(".VwiC3b").text,
"rank": i+1
})
i += 1
Run this code in your terminal. You will be able to obtain the required data from Google.
[
{
"title": "The Python Tutorial \u2014 Python 3.11.3 documentation",
"link": "https://docs.python.org/3/tutorial/",
"description": "This tutorial introduces the reader informally to the basic concepts and features of the Python language and system. It helps to have a Python interpreter\u00a0...",
"rank": 1
},
{
"title": "Python Tutorial",
"link": "https://www.w3schools.com/python/",
"description": "Learn by examples! This tutorial supplements all explanations with clarifying examples. See All Python Examples. Python Quiz. Test your Python skills with a\u00a0...",
"rank": 2
},
.....
Congratulations 🎉🎉!! You have successfully made a Python script to scrape Google Search Results.
But this method still can’t be used to scrape data from Google at a large scale, as this can result in a permanent block of your IP by Google. To counter this challenge, the scraper should be monitored consistently whether it is getting blocked or is not able to fetch data due to changes in HTML tags which Google frequently does. However, this would require a huge infrastructure which could be only made possible in the long term. That’s why businesses always prefer SERP APIs to scrape search results
Conclusion:
Overall, Python is an excellent language and offers various functionality related to web scraping. However, certain limitations exist when working with Python, such as a slower response rate when scraping Google, lack of support for multiple threads, and the risk of having your IP blocked by Google due to a high amount of requests.
It is advisable to implement an ethical strategy when dealing with Google. Alternatively, developers can integrate a Google Scraper API into their software to avoid blockage.
In this tutorial, we learned to scrape Google Search Results using Python. Feel free to message me anything you need clarification on. Follow me on Twitter. Thanks for reading!