
Walmart is the largest retail corporation in the USA, generating 572.75 Billion Dollars of revenue in 2022. With 2.2 million employees, it is the largest private employer and company by revenue.
With such a massive power in the market, its data reservoir will be as huge as its influence in the industry. This substantial data repository consists of customer reviews and product data, including pricing, features, ratings, and more. If utilized correctly, this information can lead to intelligent data-driven decisions and innovative strategies to survive in the market.
In this blog post, we will scrape Walmart using Python. We will also explore:
- How to bypass the captcha to scrape Walmart Product Page
- How to extract desired product information from Walmart
- Why is it essential to extract data from Walmart
Why Scrape Walmart?
Scraping Walmart can help you analyze product data, pricing trends, and other information. You can use the data to track prices over time to determine the rise and fall in the demand for the product.
You can extract public reviews from Walmart’s product page to identify which product is best suited for your needs, and you can also utilize this data for sentimental and market analysis purposes.
Overall, Walmart is a data-rich website for data miners. The data can be used for countless purposes. But, for now, let us focus on extracting the product information from Walmart.
Let’s Start Scraping Walmart Product Data
Let us begin by installing the libraries we may need in this tutorial.
We will be using two libraries in this tutorial: Requests and BeautifulSoup.
Requests will be used to create an HTTP connection with the web page, and BeautifulSoup will be used to parse and extract the desired information from the extracted HTML data.
To install both libraries, run the below commands in your project folder terminal:
pip install requests
pip install beautifulsoup4
It is advisable to create a list of elements you wish to scrape from the target web page. In this blog, we will focus on getting the following elements from the web page:
- Name of the product
- Price
- Rating
- Images
- Description
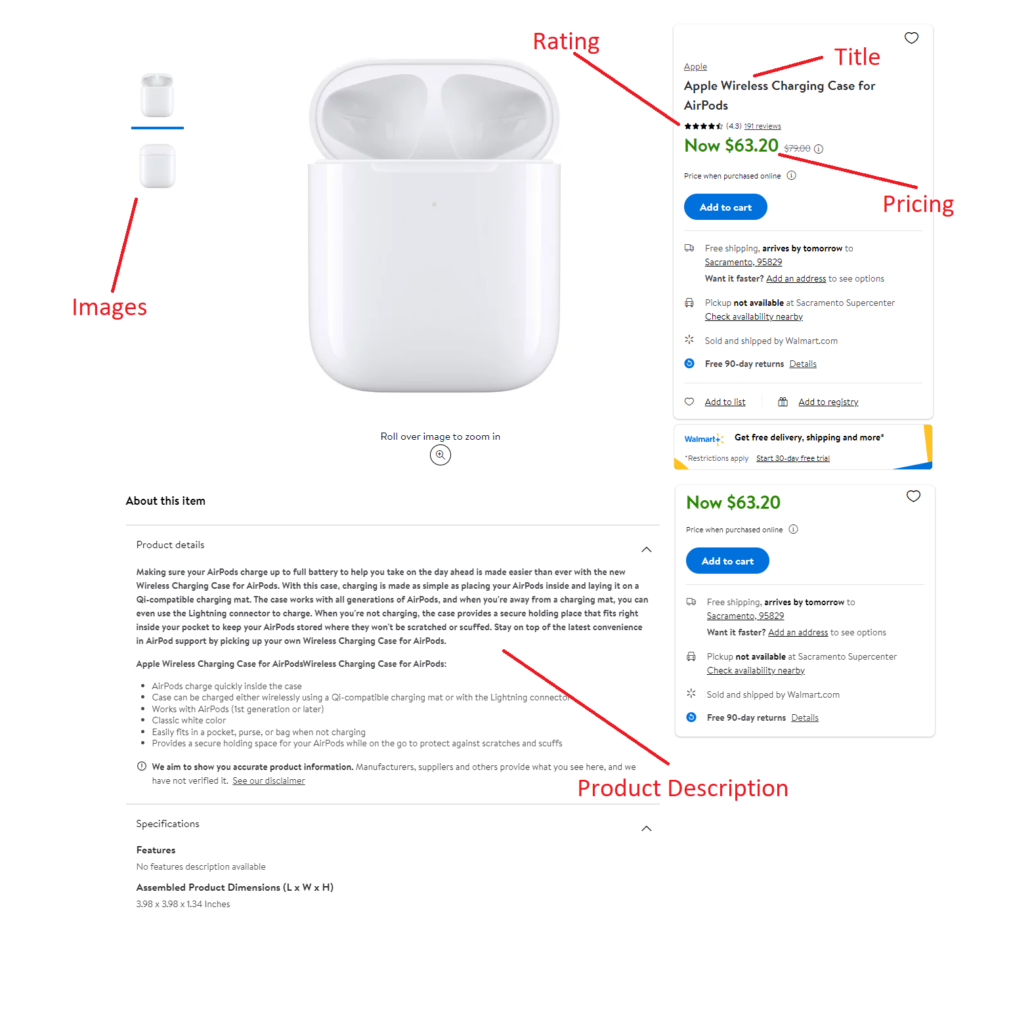
For extracting data from the HTML, we are using the BeautifulSoup library. But before we begin, we need to find the location of the elements from the HTML code we want to get in our response.
You can do this by inspecting the target element in your browser, which will help you find the location accurately. Let us start by locating the title of the product.
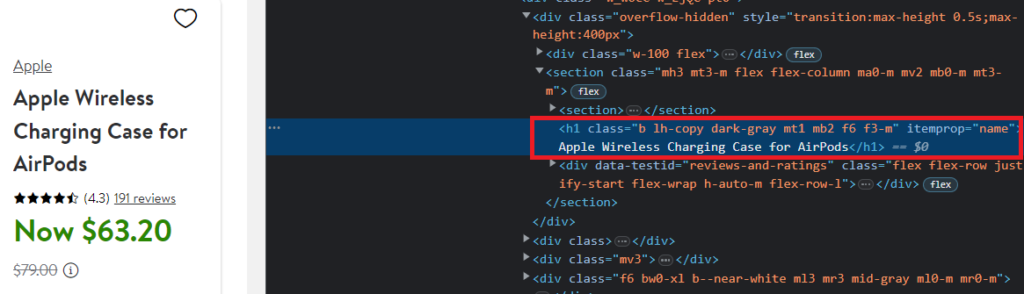
As you can see, the name of the product can be found under the tag h1 and with the attribute itemprop.
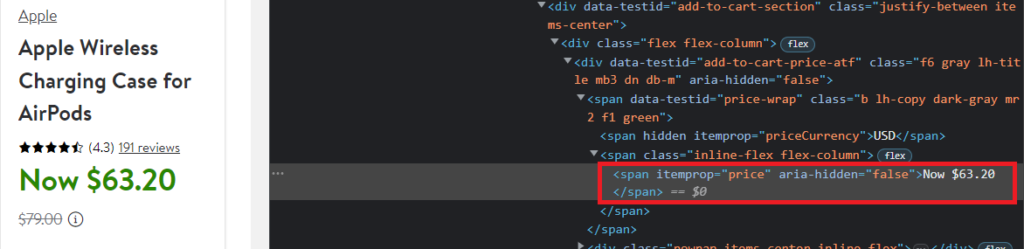
The pricing of the product is under the span tag with the attribute itemprop=“price”.
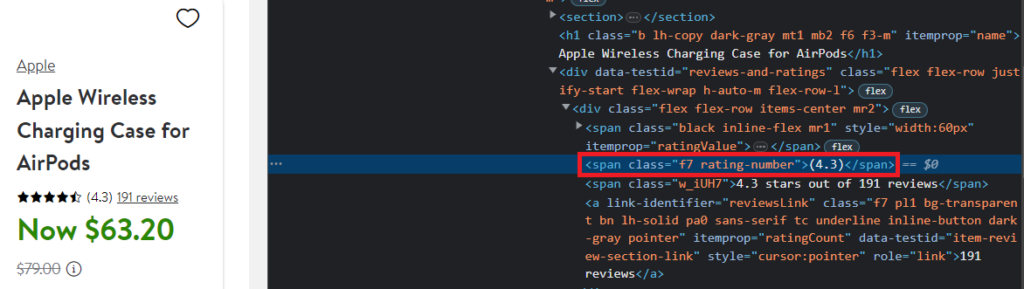
The rating is under the span tag with class rating-number.
Then, we can find the location of the product description also.
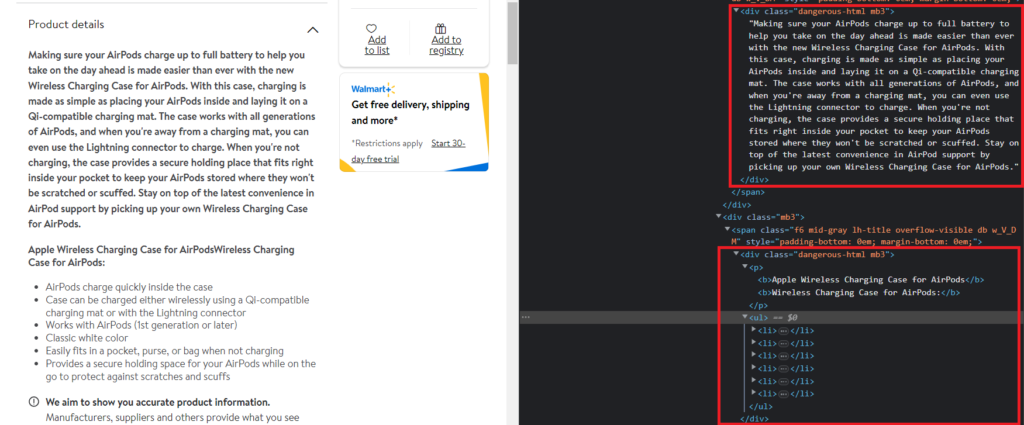
So, the product description is under the div tag with class dangerous-html.
Similarly, you can find the tags for the images also.
Let us begin by making an HTTP GET request on the target website.
import requests
from bs4 import BeautifulSoup
url= "https://www.walmart.com/ip/Apple-Wireless-Charging-Case-for-AirPods/910249719"
resp = requests.get(url).text
print(resp)
Run this code in your terminal, and you will see some greetings from the Walmart anti-bot mechanism.
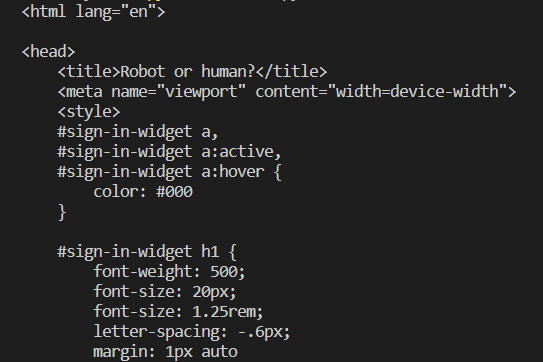
The Walmart anti-bot mechanism is intelligent. It can easily differentiate between requests from bots and humans. To bypass this CAPTCHA, we need to put some headers in our GET request so our bot can mimic an organic user.
If you want to learn about headers in detail, you can prefer this guide: Web Scraping With Python
So, let us put some headers with the GET request.
import requests
from bs4 import BeautifulSoup
url= "https://www.walmart.com/ip/Apple-Wireless-Charging-Case-for-AirPods/910249719"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
resp = requests.get(url).text
print(resp)
This would return the following output.

So, the first step is completed. Next, we will move on to get the desired information.
First, we will create a BeautifulSoup object from the HTML in resp.text. After that, we will write the code to parse every element from the HTML we discussed above.
soup = BeautifulSoup(resp.text,'html.parser')
title = soup.find("h1",{"itemprop":"name"}).text
We have already discussed the location of these elements in the above section.
Next, we will get the pricing of the product.
soup.find("span",{"itemprop":"price"}).text.replace("Now ","")
Similarly, we can get the rating and sample images of the product.
rating = soup.find("span",{"class":"rating-number"}).text.replace("(","").replace(")","")
images = []
for el in soup.select('.tc .relative'):
images.append("https" + el.find("img")['src'])
Finally, we will extract the product description. The process to scrape the product description will differ from others, where you have to inspect and locate the element and then implement the code to get the data.
When we were finding the location of the elements, I told you that the product description is under the div tag with class dangerous-html. But, if you search this class in the HTML returned by Walmart, you will not be able to find it.
This is because the product description on the Walmart product page is loaded with the help of JavaScript Rendering. Initially, the page is rendered on the server using Next JS, and then the JavaScript code is executed on the client side to render additional data.
Here is the solution. Walmart returns complete data about the product in a script tag in JSON format with id __NEXT_DATA__.
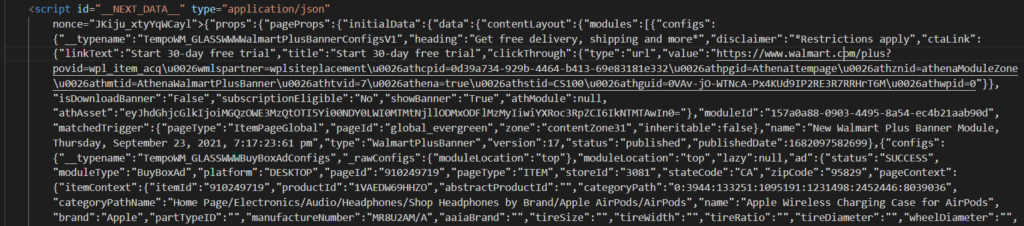
This also contains a description of the product. Let us access the JSON data through our scraper.
import json
script_data = soup.find('script', {'id': '__NEXT_DATA__'})
json = json.loads(script_data.text)
This will return the complete JSON data. Now, search for the initials of the product description in the returned data to figure out its exact location. This is how you can extract it:
product_description = json['props']['pageProps']['initialData']['data']['product']['shortDescription']

So, we are done with our target elements. If you want more information about the product, you can use this JSON data to extract more data.
Complete code:
import requests
from bs4 import BeautifulSoup
import json
url="https://www.walmart.com/ip/Apple-Wireless-Charging-Case-for-AirPods/910249719"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
resp = requests.get(url, headers=headers)
print(resp.status_code)
soup = BeautifulSoup(resp.text,'html.parser')
title = soup.find("h1").text
pricing = soup.find("span",{"itemprop":"price"}).text.replace("Now ","")
rating = soup.find("span",{"class":"rating-number"}).text.replace("(","").replace(")","")
images = []
for el in soup.select('.tc .relative'):
images.append("https" + el.find("img")['src'])
script_data = soup.find('script', {'id': '__NEXT_DATA__'})
json = json.loads(script_data.text)
product_description = json['props']['pageProps']['initialData']['data']['product']['shortDescription']
You can also make changes to the script according to your needs.
Scraping Walmart Using Serpdog
Walmart is tough to scrape with limited resources. They can quickly block your IP if you attempt to scrape millions of pages from their server. Simply passing appropriate headers with the request won’t provide a long-term solution.
Ultimately, it is essential to use a large number of rotating IPs for scraping Walmart. Maintaining the scraper becomes time-consuming over the long period, which is why we offer you an excellent solution for scraping Walmart: Serpdog’s Web Scraping API
Serpdog also offers 1000 free API requests on the sign-up.
After successfully getting registered, you will get an API Key to access our API services. You can embed your API Key in the below code to extract data from Walmart without using any IP pool and headers.
import requests
from bs4 import BeautifulSoup
import json
url="https://api.serpdog.io/scrape?api_key=APIKEY&url=https://www.walmart.com/ip/Apple-Wireless-Charging-Case-for-AirPods/910249719&render_js=false"
resp = requests.get(url)
print(resp.status_code)
soup = BeautifulSoup(resp.text,'html.parser')
title = soup.find("h1").text
pricing = soup.find("span",{"itemprop":"price"}).text.replace("Now ","")
rating = soup.find("span",{"class":"rating-number"}).text.replace("(","").replace(")","")
images = []
for el in soup.select('.tc .relative'):
images.append("https" + el.find("img")['src'])
script_data = soup.find('script', {'id': '__NEXT_DATA__'})
json = json.loads(script_data.text)
product_description = json['props']['pageProps']['initialData']['data']['product']['shortDescription']
Conclusion
In this tutorial, we learned to scrape Amazon Product Data using Python. Please do not hesitate to message me if I missed something.
If you think we can complete your custom scraping projects, please do not hesitate to reach out to us. Follow me on Twitter. Thanks for reading!
Additional Resources
I have prepared a complete list of blogs on web scraping, which can help you in your data extraction journey: